CPU缓存一致性:从理论到实战


目录存储体系结构缓存原理缓存一致性协议内存屏障x86-TSO基准测试CAS原理原子操作无锁队列参考资料01存储体系结构速度快的存储硬件成本高、容量小,速度慢的成本低、容量大。为了权衡成本和速度,计算机......
目录
存储体系结构
缓存原理
缓存一致性协议
内存屏障
x86-TSO
基准测试
CAS原理
原子操作
无锁队列
参考资料
01
存储体系结构
速度快的存储硬件成本高、容量小,速度慢的成本低、容量大。为了权衡成本和速度,计算机存储分了很多层次,扬长避短,有寄存器、L1cache、L2cache、L3cache、主存(内存)和硬盘等。图1展示了现代存储体系结构。

图1
根据程序的空间局部性和时间局部性原理,缓存命中率可以达到70~90%。因此,增加缓存可以让整个存储系统的性能接近寄存器,并且每字节的成本都接近内存,甚至是磁盘。
所以缓存是存储体系结构的灵魂。
02
缓存原理
2.1缓存的工作原理
cacheline(缓存行)是缓存进行管理的最小存储单元,也叫缓存块,每个cacheline包含Flag、Tag和Data,通常Data大小是64字节,但不同型号CPU的Flag和Tag可能不相同。从内存向缓存加载数据是按整个缓存行加载的,一个缓存行和一个相同大小的内存块对应。
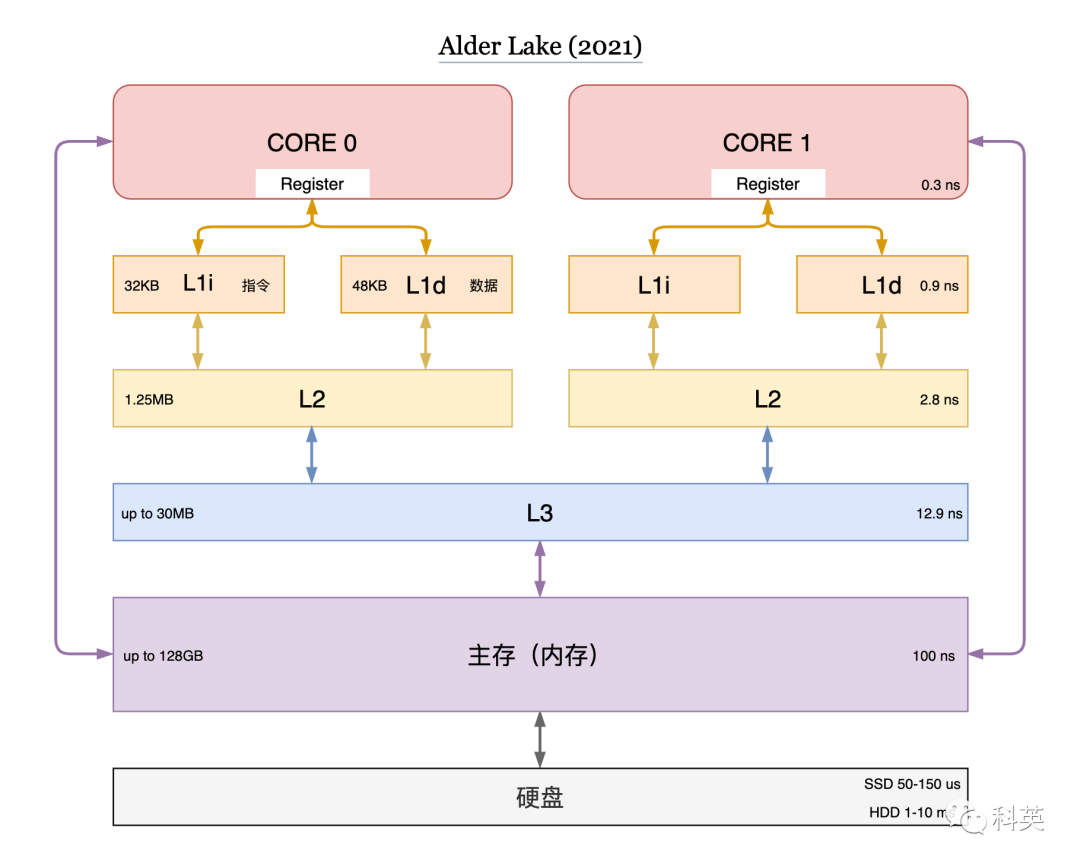
图2
图2中,缓存是按照矩阵方式排列(M×N),横向是组(Set),纵向是路(Way)。每一个元素是缓存行(cacheline)。
那么给定一个虚拟地址addr如何在缓存中定位它呢?首先把它所在的组号找到,即:
//左移6位是因为BlockOffset占addr的低6位,Data为64字节SetIndex=(addr6)%M;
然后遍历该组所有的路,找到cacheline中的Tag与addr中Tag相等为止,所有路都没有匹配成功,那么缓存未命中。
整个缓存容量=组数×路数×缓存行大小
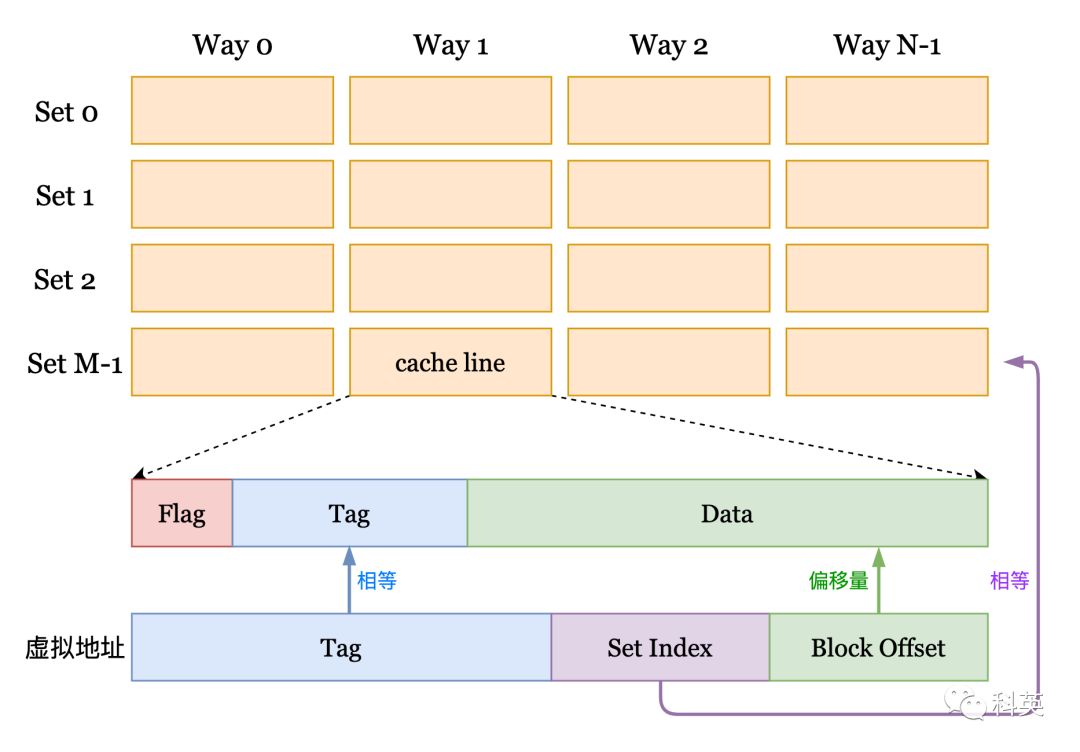
我电脑的CPU信息:
我电脑的缓存信息:
通过缓存行大小和路数可以倒推出缓存的组数,即:
缓存组数=整个缓存容量÷路数÷缓存行大小
2.2缓存行替换策略
目前最常用的缓存替换策略是最近最少使用算法(LeastRecentlyUsed,LRU)或者是类似LRU的算法。
LRU算法比较简单,如图3,缓存有4路,并且访问的地址都哈希到了同一组,访问顺序是D1、D2、D3、D4和D5,那么D1会被D5替换掉。算法的实现方式有很多种,最简单的实现方式是位矩阵。
首先,定义一个行、列都与缓存路数相同的矩阵。当访问某个路对应的缓存行时,先将该路对应的所有行置为1,然后再将该路对应的所有列置为0。
最近最少使用的缓存行所对应的矩阵行中1的个数最少,最先被替换出去。
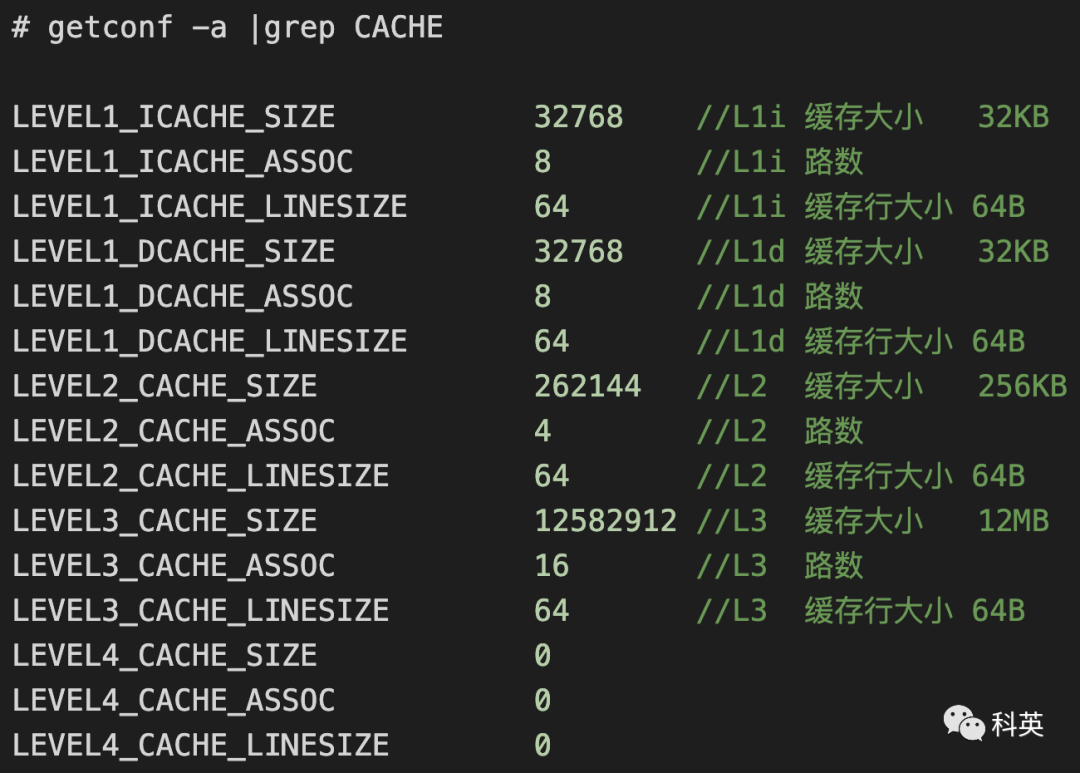
图3
2.3缓存缺失
缓存缺失就是缓存未命中,需要把内存中数据加载到缓存,所以运行速度会变慢。
就拿我的电脑来测试,L1d的缓存大小是32KB(32768B),8路,缓存行大小64B,那么
缓存组数=32×1024÷8÷64=64
运行下面的代码
char*a=newchar(64*64*8);//32768Bfor(inti=0;i20000000;i++)for(intj=0;j32768;j+=4096)a[j]++;
结果:循环160000000次,耗时301ms。除了第一次未命中缓存,后面每次读写数据都能命中缓存。
调整上面的代码,并运行
char*a=newchar(64*64*8*2);//65536Bfor(inti=0;i10000000;i++)for(intj=0;j65536;j+=4096)a[j]++;
结果:循环160000000次,耗时959ms。每一次读写数据都没有命中缓存,所以耗时增加了2倍。
2.4程序局部性
程序局部性就是读写内存数据时读写连续的内存空间,目的是让缓存可以命中,减少缓存缺失导致替换的开销。
我电脑上运行下面代码
intM=10000,N=10000;char(*a)[N]=(char(*)[N])calloc(M*N,sizeof(char));for(inti=0;iM;i++)for(intj=0;jN;j++)a[i][j]++;
结果:循环100000000次,耗时314ms。利用了程序局部性原理,缓存命中率高。
修改上面的代码如下,并运行
intM=10000,N=10000;char(*a)[N]=(char(*)[N])calloc(M*N,sizeof(char));for(intj=0;jN;j++)for(inti=0;iM;i++)a[i][j]++;
结果:循环100000000次,耗时1187ms。没有利用程序局部性原理,缓存命中率低,所以耗时增加了2倍。
2.5伪共享(false-sharing)
当两个线程同时各自修改两个相邻的变量,由于缓存是按缓存行来整体组织的,当一个线程对缓存行中数据执行写操作时,必须通知其他线程该缓存行失效,导致另一个线程从缓存中读取其想修改的数据失败,必须从内存重新加载,导致性能下降。
我电脑运行下面代码
structS{longlonga;longlongb;}s;std::threadt1([](){for(inti=0;i100000000;i++)++;});std::threadt2([](){for(inti=0;i100000000;i++)++;});结果:耗时512ms,原因上面提到了,就是两个线程互相影响,使对方的缓存行失效,导致直接从内存读取数据。
解决办法是对上面代码做如下修改:
structS{longlonga;longlongnoop[8];longlongb;}s;结果:耗时181ms,原因是通过longlongnoop[8]把两个数据(a和b)划分到两个不同的缓存行中,不再互相使对方的缓存失效,所以速度变快了。
本小节的测试代码都没有开启编译器优化,即编译选项为-O0。
03
缓存一致性协议
在单核时代,增加缓存可以大大提高读写速度,但是到了多核时代,却引入了缓存一致性问题,如果有一个核心修改了缓存行中的某个值,那么必须有一种机制保证其他核心能够观察到这个修改。
3.1缓存写策略
从缓存和内存的更新关系来看,分为:
写回(write-back)对缓存的修改不会立刻传播到内存,只有当缓存行被替换时,这些被修改的缓存行才会写回并覆盖内存中过时的数据。
写直达(writethrough)缓存中任何一个字节的修改,都会立刻穿透缓存直接传播到内存,这种比较耗时。
从写缓存时CPU之间的更新策略来看,分为:
写更新(WriteUpdate)每次缓存写入新的值,该核心必须发起一次总线请求,通知其他核心更新他们缓存中对应的值。
坏处:写更新会占用很多总线带宽;
好处:其他核心能立刻获得最新的值。
写无效(WriteInvalidate)每次缓存写入新的值,都将其他核心缓存中对应的缓存行置为无效。
坏处:当其他核心再次访问该缓存时,发现缓存行已经失效,必须从内存中重新载入最新的数据;
好处:多次写操作只需发一次总线事件,第一次写已经将其他核心缓存行置为无效,之后的写不必再更新状态,这样可以有效地节省核心间总线带宽。
从写缓存时数据是否被加载来看,分为:
写分配(WriteAllocate)在写入数据前将数据读入缓存。当缓存块中的数据在未来读写概率较高,也就是程序空间局部性较好时,写分配的效率较好。
写不分配(NotWriteAllocate)在写入数据时,直接将数据写入内存,并不先将数据块读入缓存。当数据块中的数据在未来使用的概率较低时,写不分配性能较好。
3.2MESI协议
MESI协议是⼀个基于失效的缓存⼀致性协议,是⽀持写回(write-back)缓存的最常⽤协议。也称作伊利诺伊协议(Illinoisprotocol,因为是在伊利诺伊⼤学厄巴纳-⾹槟分校被发明的)。
为了解决多个核心之间的数据传播问题,提出了总线嗅探(BusSnooping)策略。本质上就是把所有的读写请求都通过总线(Bus)广播给所有的核心,然后让各个核心去嗅探这些请求,再根据本地的状态进行响应。
3.2.1状态
已修改Modified(M):缓存⾏是脏的,与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存⾏必须回写到主存,状态变为共享(S).
独占Exclusive(E):缓存⾏只在当前缓存中,但是⼲净的,缓存数据等于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
共享Shared(S):缓存⾏也存在于其它缓存中且是⼲净的。缓存⾏可以在任意时刻抛弃。
⽆效Invalid(I):缓存⾏是⽆效的。
这些状态信息实际上存储在缓存行(cacheline)的Flag里。
3.2.2事件
处理器对缓存的请求:
PrRd:核心请求从缓存块中读出数据;
PrWr:核心请求向缓存块写入数据。
总线对缓存的请求:
BusRd:总线嗅探器收到来自其他核心的读出缓存请求;
BusRdX:总线嗅探器收到另一核心写⼀个其不拥有的缓存块的请求;
BusUpgr:总线嗅探器收到另一核心写⼀个其拥有的缓存块的请求;
Flush:总线嗅探器收到另一核心把一个缓存块写回到主存的请求;
FlushOpt:总线嗅探器收到一个缓存块被放置在总线以提供给另一核心的请求,和Flush类似,但只不过是从缓存到缓存的传输请求。
3.2.3状态机
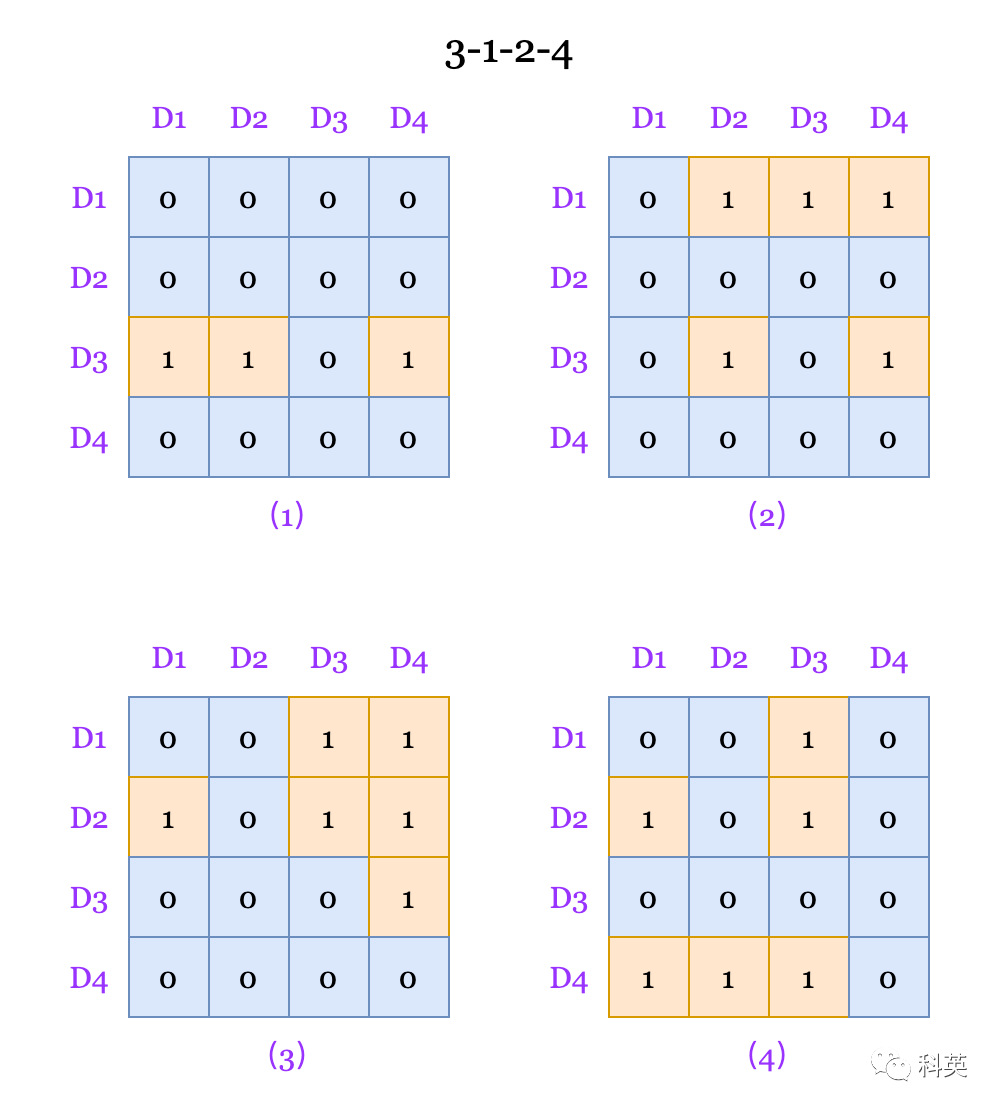
图4
表1是对状态机图4的详解讲解(选读)
当前状态事件
响应
M
PrRd⽆总线事务⽣成
状态保持不变
读操作为缓存命中
PrWr⽆总线事务⽣成
状态保持不变
写操作为缓存命中
BusRd状态变为共享(S)Shared
发出总线FlushOpt信号并发出块的内容,接收者为最初发出BusRd的缓存与主存控制器(回写主存)
BusRdX状态变为⽆效(I)Invalid
发出总线FlushOpt信号并发出块的内容,接收者为最初发出BusRd的缓存与主存控制器(回写主存)
E
PrRd⽆总线事务⽣成
状态保持不变
读操作为缓存命中
PrWr⽆总线事务⽣成
状态变为已修改(M)Modified
向缓存块中写⼊修改后的值
BusRd
状态变为共享(S)Shared
发出总线FlushOpt信号并发出块的内容
BusRdX
状态变为⽆效
发出总线FlushOpt信号并发出块的内容
SPrRd⽆总线事务⽣成
状态保持不变
读操作为缓存命中
PrWr
发出总线事务BusUpgr信号
状态转换为已修改(M)Modified
其他缓存看到BusUpgr总线信号,标记其副本为为无效(I)Invalid
BusRd状态变为共享(S)Shared
可能发出总线FlushOpt信号并发出块的内容(设计时决定那个共享的缓存发出数据)
BusRdX
状态变为⽆效(I)Invalid
可能发出总线FlushOpt信号并发出块的内容(设计时决定那个共享的缓存发出数据)
IPrRd
给总线发BusRd信号
其他处理器看到BusRd,检查⾃⼰是否有有效的数据副本,通知发出请求的缓存
如果其他缓存有有效的副本,其中⼀个缓存发出数据,状态变为(S)Shared
如果其他缓存都没有有效的副本,从主存获得数据,状态变为(E)Exclusive
PrWr
给总线发BusRdX信号
状态转换为(M)Modified
如果其他缓存有有效的副本,其中⼀个缓存发出数据;否则从主存获得数据
如果其他缓存有有效的副本,⻅到BusRdX信号后⽆效其副本
向缓存块中写⼊修改后的值
BusRd
状态保持不变,信号忽略
BusRdX/BusUpgr
状态保持不变,信号忽略
表1
3.2.4动画演示
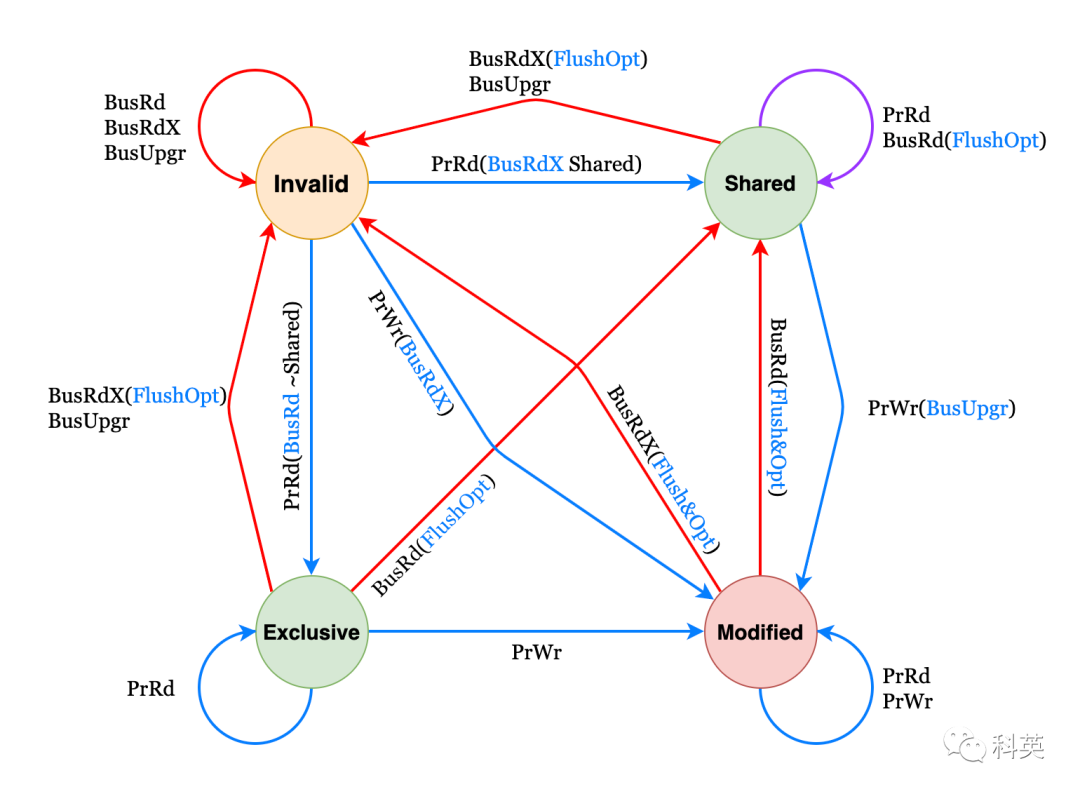
图5
各家CPU厂商没有都完全按照MESI实现缓存一致性协议,导致MESI有很多变种,例如:Intel采用的MESIF和AMD采用的MOESI,ARM大部分采用的是MESI,少部分使用的是MOESI。
3.3MOESI协议(选读)
MOESI是一个完整的缓存一致性协议,它包含了其他协议中常用的所有可能状态。除了四种常见的MESI协议状态之外,还有第五种Owned状态,表示修改和共享的数据。
这就避免了在共享数据之前将修改过的数据写回主存的需要。虽然数据最终仍然必须写回,但写回可能是延迟的。
已修改Modified(M):缓存⾏是脏的(dirty),与主存的值不同,并且缓存具有系统中唯一有效数据。处于修改状态的缓存可以将数据提供给另一个读取器,而无需将其传输到内存,然后状态变为O,读取者变为S。
拥有Owned(O):缓存⾏是脏的(dirty),与主存的值不同,但不是系统中唯一有效副本,一定存在其他的S。为其他核心提供读请求,较少核心间总线带宽。
独占Exclusive(E):缓存⾏只在当前缓存中,但是⼲净的(clean),缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
共享Shared(S):缓存⾏也存在于其它缓存中且不一定是⼲净的。如果O存在,就是脏的,反之亦然。
⽆效Invalid(I):缓存⾏是⽆效的。
3.4MESIF协议(选读)
MESIF是一个缓存一致性和记忆连贯协议,该协议由五个状态组成:已修改(M),互斥(E),共享(S),无效(I)和转发(F)。
M,E,S和I状态与MESI协议一致。F状态是S状态的一种特殊形式,当系统中有多个S时,必须选取一个转换为F,只有F状态的负责应答。通常是最后持有该副本的转换为F,注意F是干净的数据。
该协议与MOESI协议有较大的不同,也远比MOESI协议复杂。该协议由Intel的快速通道互联QPI(QuickPathInterconnect)技术引入,其主要目的是解决“基于点到点互联的非一致性内存访问(Non-uniformmemoryaccess,NUMA)处理器系统”的缓存一致性问题,而不是“基于共享总线的一致性内存访问(UniformMemoryAccess,UMA)处理器系统”的缓存一致性问题。
04
内存屏障(MemoryBarriers)
编译器和处理器都必须遵守重排序规则。在单处理器的情况下,不需要任何额外的操作便能保持正确的顺序。但是对于多处理器来说,保证一致性通常需要增加内存屏障指令。即使编译器可以优化掉字段的访问(例如因为未使用加载到的值),编译器仍然需要生成内存屏障,就好像字段访问仍然存在一样(可以单独将内存屏障优化掉)。
内存屏障只与内存模型中的高级概念(例如acquire和release)间接相关。内存屏障指令只直接控制CPU与其缓存的交互,以及它的写缓冲区(持有等待刷新到内存的数据的存储)和它的用于等待加载或推测执行指令的缓冲。这些影响可能导致缓存、主内存和其他处理器之间的进一步交互。
几乎所有的处理器都至少支持一个粗粒度的屏障指令(通常称为Fence,也叫全屏障),它保证了严格的有序性:在Fence之前的所有读操作(load)和写操作(store)先于在Fence之后的所有读操作(load)和写操作(store)执行完。对于任何的处理器来说,这通常都是最耗时的指令之一(它的开销通常接近甚至超过原子操作指令)。大多数处理器还支持更细粒度的屏障指令。
LoadLoadBarrier(读读屏障)
指令Load1;LoadLoad;Load2保证了Load1先于Load2和后续所有的load指令加载数据。通常情况下,在执行预测读(speculativeloads)或乱序处理(out-of-orderprocessing)的处理器上需要显式的LoadLoadBarrier。在始终保证读顺序(loadordering)的处理器上,这些屏障相当于无操作(no-ops)。
StoreStoreBarrier(写写屏障)
指令Store1;StoreStore;Store2保证了Store1的数据先于Store2及后续store指令的数据对其他处理器可见(刷新到内存)。通常情况下,在不保证严格按照顺序从写缓冲区(storebuffers)或者缓存(caches)刷新到其他处理器或内存的处理器上,需要使用StoreStoreBarrier。
LoadStoreBarrier(读写屏障)
指令Load1;LoadStore;Store2保证了Load1的加载数据先于Store2及后续store指令刷新数据到主内存。只有在乱序(out-of-order)处理器上,等待写指令(waitingstoreinstructions)可以绕过读指令(loads)的情况下,才会需要使用LoadStore屏障。
StoreLoadBarrier(写读屏障)刷新写缓冲区,最耗时
指令Store1;StoreLoad;Load2保证了Store1的数据对其他处理器可见(刷新数据到内存)先于Load2及后续的load指令加载数据。StoreLoad屏障可以防止后续的读操作错误地使用了Store1写的数据,而不是使用来自另一个处理器的更近的对同一位置的写。因此只有需要将对同一个位置的写操作(stores)和随后的读操作(loads)分开时,才严格需要StoreLoad屏障。StoreLoad屏障通常是开销最大的屏障,几乎所有的现代处理器都需要该屏障。之所以开销大,部分原因是它需要禁用绕过缓存(cache)从写缓冲区(StoreBuffer)读取数据的机制。这可以通过让缓冲区完全刷新,外加暂停其他操作来实现,这就是Fence的效果。一般用Fence代替StoreLoadBarrier,所以事实上,执行StoreLoad指令同时也获得了其他三个屏障的效果,但是通过组合其他屏障通常不能获得与StoreLoadBarrier相同的效果。
表2是各处理器支持的内存屏障和原子操作
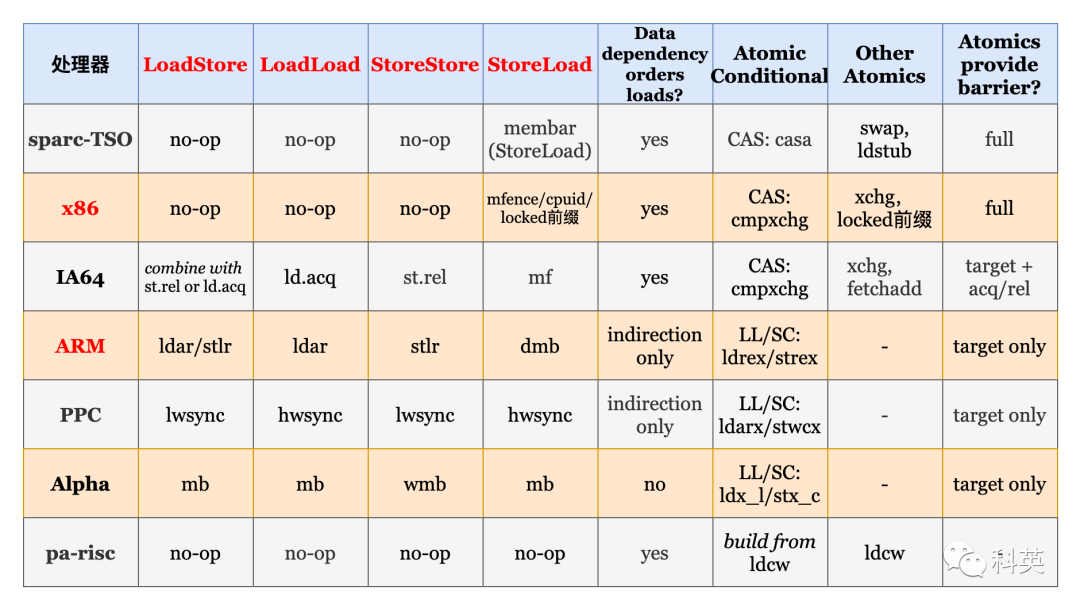
表2
4.1写缓冲与写屏障
严格按照MESI协议,核心0在修改本地缓存之前,需要向其他核心发送Invalid消息,其他核心收到消息后,使他们本地对应的缓存行失效,并返回Invalidacknowledgement消息,核心0收到后修改缓存行。这里核心0等待其他核心返回确认消息的时间对核心来说是漫长的。
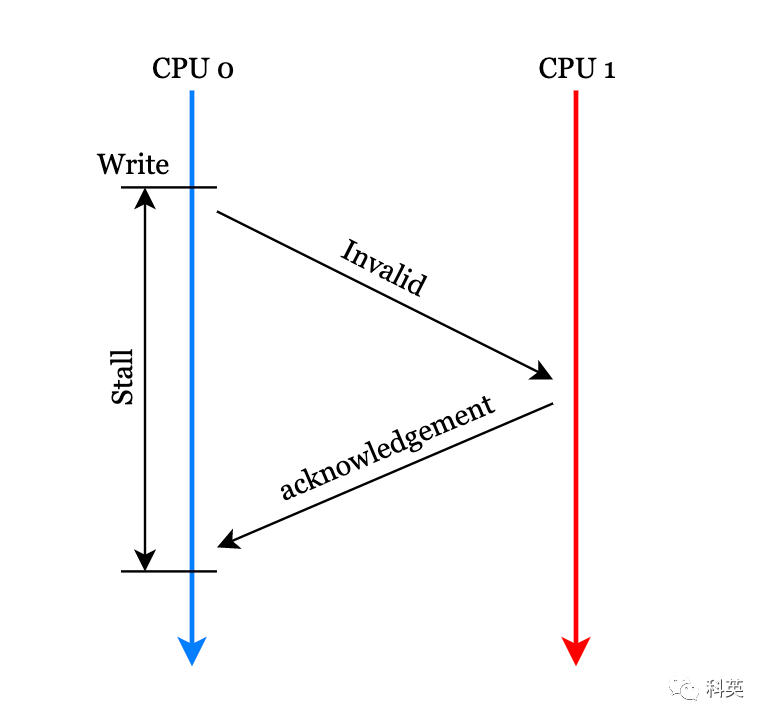
图6
为了解决这个问题,引入了StoreBuffer,当核心想修改缓存时,直接写入Storeuffer,无需等待,继续处理其他事情,由StoreBuffer完成后续工作。
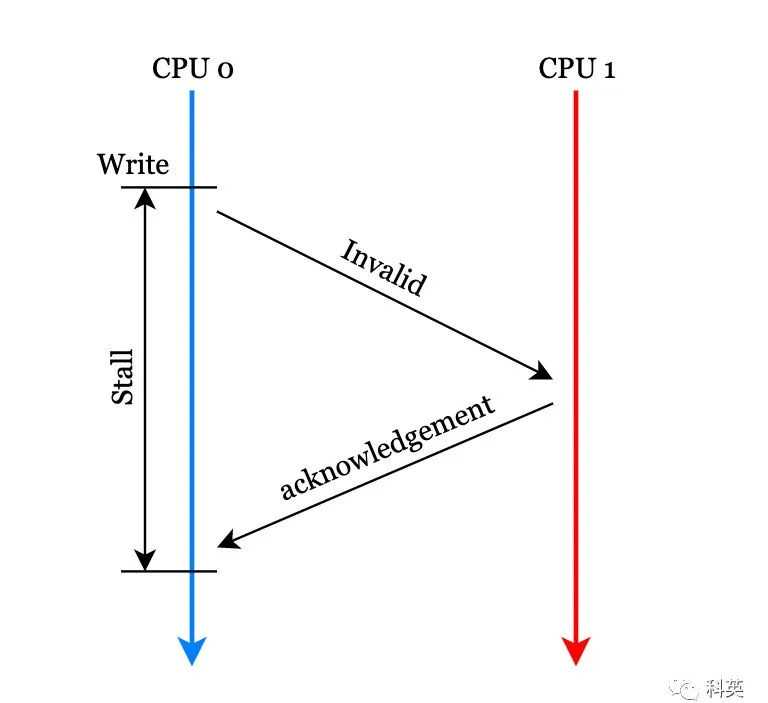
图7
这样一来写的速度加快了,但是引来了新问题,下面代码的bar函数中的断言可能会失败。
inta=0,b=0;//CPU0voidfoo(){a=1;b=1;}//CPU1voidbar(){while(b==0)continue;assert(a==1);}第一种情况:CPU为了提升运行效率和提高缓存命中率,采用了乱序执行;
第二种情况:StoreBuffer在写入时,b所对应的缓存行是E状态,a所对应的缓存行是S状态,因为对b的修改不需要核心间同步,但是修改a则需要,也就是b会先写入缓存。与之对应CPU1中a是S状态,b是I状态,由于b所对应的缓存区域是I状态,它就会向总线发出BusRd请求,那么CPU1就会先把b的最新值读到本地,完成变量b值的更新,但是从缓存直接读取a值是0。
举一个更极端的例子
//CPU0voidfoo(){a=1;b=a;}第一种情况不会发生了,原因是代码有依赖,不会乱序执行。但由于StoreBuffer的存在,第二种情况仍然可能发生,原因同上。这会让人感到更加匪夷所思。
为了解决上面问题,引入了内存屏障,屏障的作用是前边的读写操作未完成的情况下,后面的读写操作不能发生。这就是Arm上dmb指令的由来,它是数据内存屏障(DataMemoryBarrier)的缩写。
inta=0,b=0;//CPU0voidfoo(){a=1;smp_mb();//内存屏障,各CPU平台实现不一样b=1;}//CPU1voidbar(){while(b==0)continue;assert(a==1);}加上内存屏障后,保证了a和b的写入缓存顺序。
总的来说,StoreBuffer提升了写性能,但放弃了缓存的顺序一致性,这种现象称为弱缓存一致性。通常情况下,多个CPU一起操作同一个变量的情况是比较少的,所以StoreBuffer可以大幅提升程序的性能。但在需要核间同步的情况下,还是需要通过手动添加内存屏障来保证缓存一致性。
上面解决了核间同步的写问题,但是核间同步还有一个瓶颈,那就是读。
4.2失效队列与读屏障
前面引入StoreBuffer提升了写入速度,那么invalid消息确认速度相比起来就慢了,带来了速度不匹配,很容易导致StoreBuffer的内容还没及时写到缓存里,自己就满了,从而失去了加速的作用。
为了解决这个问题,又引入了InvalidQueue。收到Invalid消息的核心立刻返回Invalidacknowledgement消息,然后把Invalid消息加入InvalidQueue,等到空闲的时候再去处理Invalid消息。
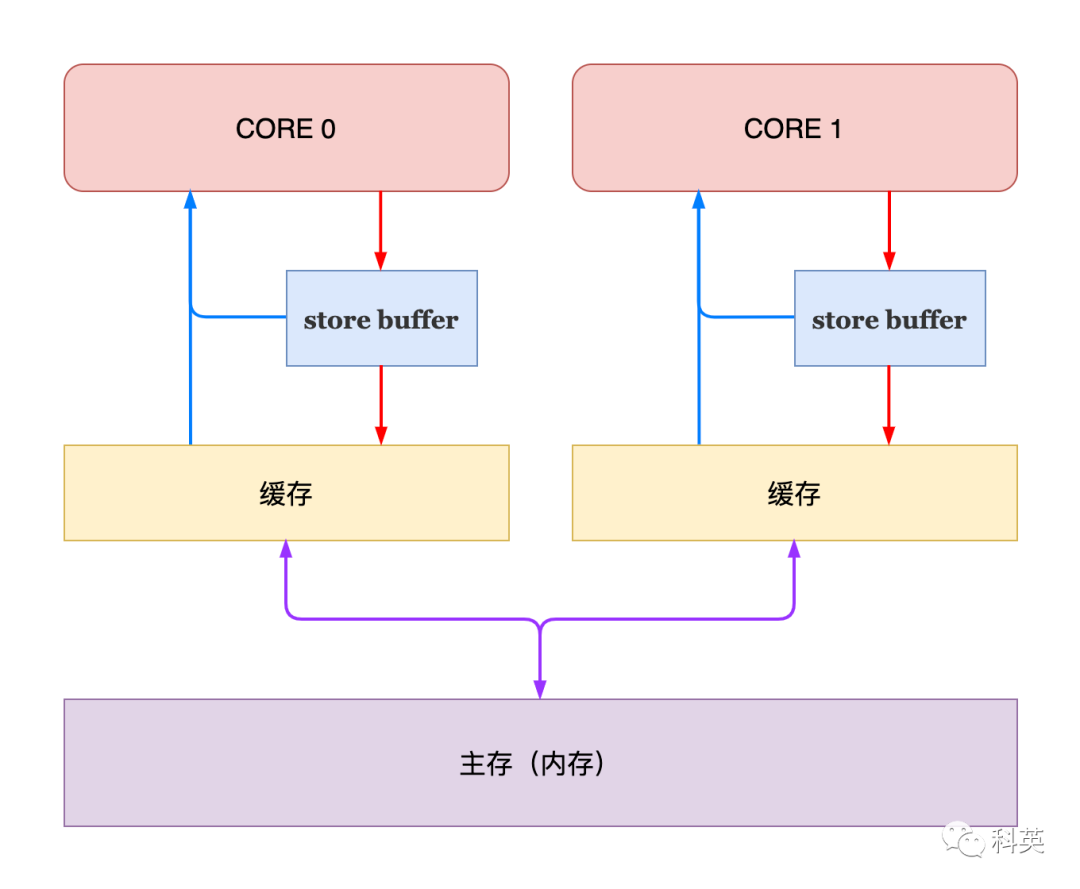
图8
运行上面增加内存屏障的代码,第11行的断言又可能失败了。
核心0中a所对应的缓存行是S状态,b所对应的缓存行是E状态;核心1中a所对应的缓存行是S状态,b所对应的缓存行是I状态;
因为有内存屏障在,a和b的写入缓存的顺序不会乱。
a先向其他核心发送Invalid消息,并且等待Invalid确认消息;
Invalid消息先入核心1对应的InvalidQueue并立刻返回确认消息,等待核心1处理;
核心0收到确认消息后把a写入缓存,继续处理b的写入,由于b是E状态,直接写入缓存;
核心1发送BusRd消息,读取到新的b值,然后获取a(S状态)值是0,因为使其无效的消息还在InvalidQueue中,第11行断言失败。
引入InvalidQueue后,对核心1来说看到的a和b的写入又出现乱序了。
解决办法是继续加内存屏障,核心1想越过屏障必须清空InvalidQueue,及时处理了对a的无效,然后读取到新的a值,如下代码:
inta=0,b=0;//CPU0voidfoo(){a=1;smp_mb();b=1;}//CPU1voidbar(){while(b==0)continue;smp_mb();//继续加内存屏障assert(a==1);}这里使用的内存屏障是全屏障,包括读写屏障,过于严格了,会导致性能下降,所以有了细粒度的读屏障和写屏障。
4.3读写屏障分离
分离的写屏障和读屏障的出现,是为了更加精细地控制StoreBuffer和InvalidQueue的顺序。
读屏障不允许其前后的读操作越过屏障;
写屏障不允许其前后的写操作越过屏障;
优化前面的代码如下
inta=0,b=0;//CPU0voidfoo(){a=1;smp_wmb();//写屏障b=1;}//CPU1voidbar(){while(b==0)continue;smp_rmb();//读屏障assert(a==1);}这种修改只有在区分读写屏障的体系结构里才会有作用,比如alpha结构。在x86和Arm中是没有作用的,因为x86采用了TSO模型,后面会详细介绍,而Arm采用了单向屏障。
4.4单向屏障
单向屏障(half-waybarrier)也是一种内存屏障,但它不是以读写来区分的,而是像单行道一样,只允许单向通行,例如ARM中的stlr和ldar指令就是这样。
stlr的全称是storereleaseregister,包括StoreStorebarrier和LoadStorebarrier(场景少),通常使用release语义将寄存器的值写入内存;
ldar的全称是loadacquireregister,包括LoadLoadbarrier和LoadStorebarrier(对,你没看错,我没写错),通常使用acquire语义从内存中将值加载入寄存器;
release语义的内存屏障只不允许其前面的读写向后越过屏障,挡前不挡后;
acquire语义的内存屏障只不允许其后面的读写向前越过屏障,挡后不挡前;
StoreLoadbarrier就只能使用dmb(全屏障)代替了。
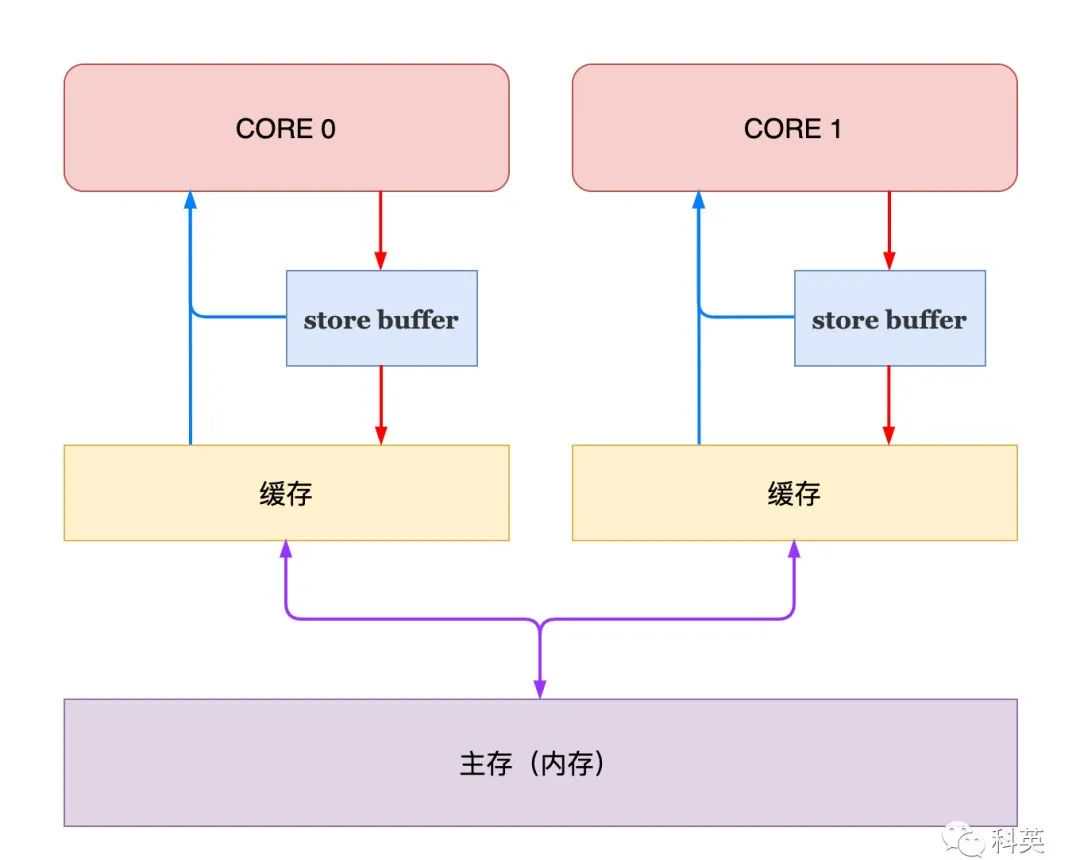
图9
理论普及的差不多了,接下单独来说说服务端同学工作中最常用的x86内存模型,填一下4.3中留下的坑。
05
x86-TSO
x86-TSO(TotalStoreOrder)采用的是图10模型。
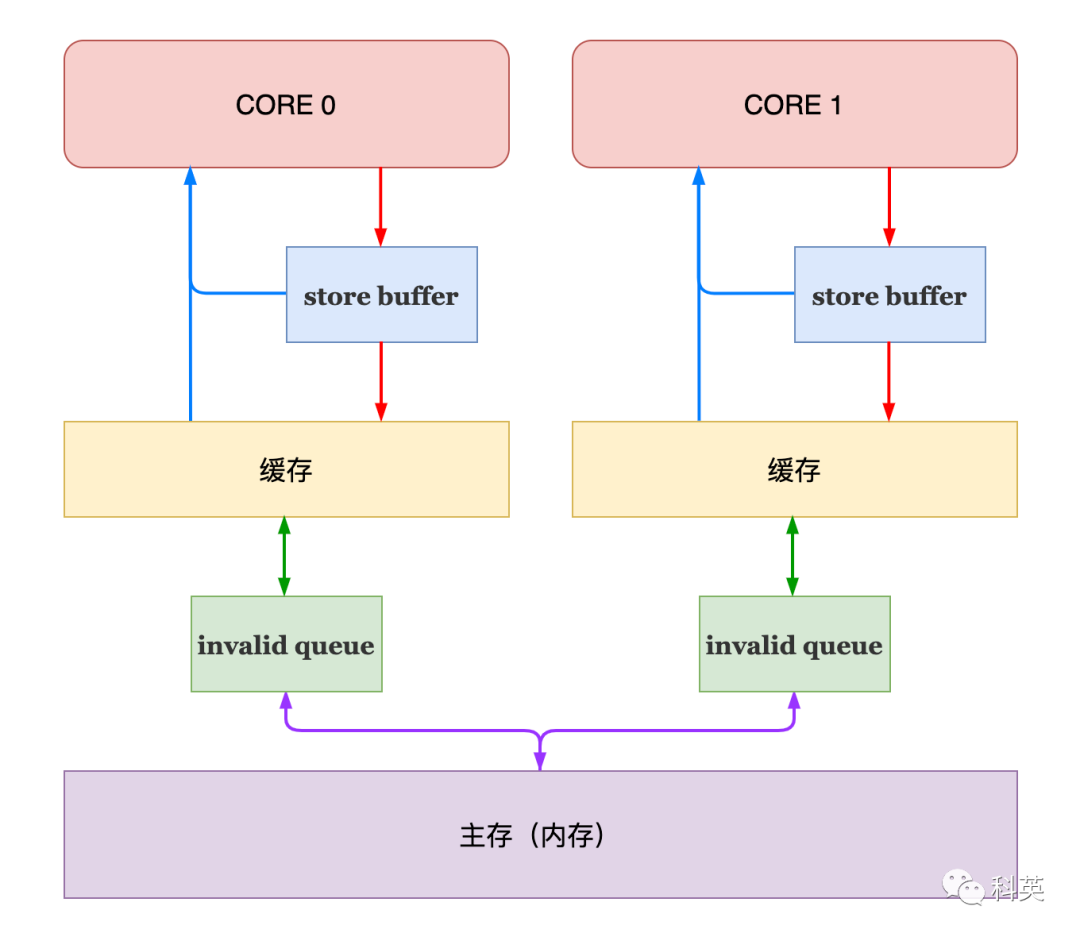
图10
x86-TSO有下面几个特点:
StoreBuffer被实现为FIFO队列,CPU务必优先读取本地StoreBuffer中的值(如果有的话),否则去缓存或内存里读取;
因为StoreBuffer是FIFO,所以写写不会重排,也就不需要StoreStorebarrier;
MFENCE指令用于清空本地StoreBuffer,并将数据刷到缓存和内存;
某CPU执行lock前缀的指令时,会去争抢全局锁,拿到锁后其他线程的读取操作会被阻塞,在释放锁之前,会清空该线程的本地的StoreBuffer,这里和MFENCE执行逻辑类似;
StoreBuffer被写入变量后,除了被其他线程持有锁以外的情况,在任何时刻均有可能写回内存。
因为没有引入InvalidQueue,所以不需要LoadLoadbarrier;
LoadStorebarrier仅在乱序(out-of-order)处理器上有效,因为等待写指令可以绕过读指令;而x86-TSO相对其他平台缓存一致性是最严格的,读操作不会延后,不会使读写重排;
那么最后只有StoreLoadbarrier是有效的,其他屏障都是no-op。
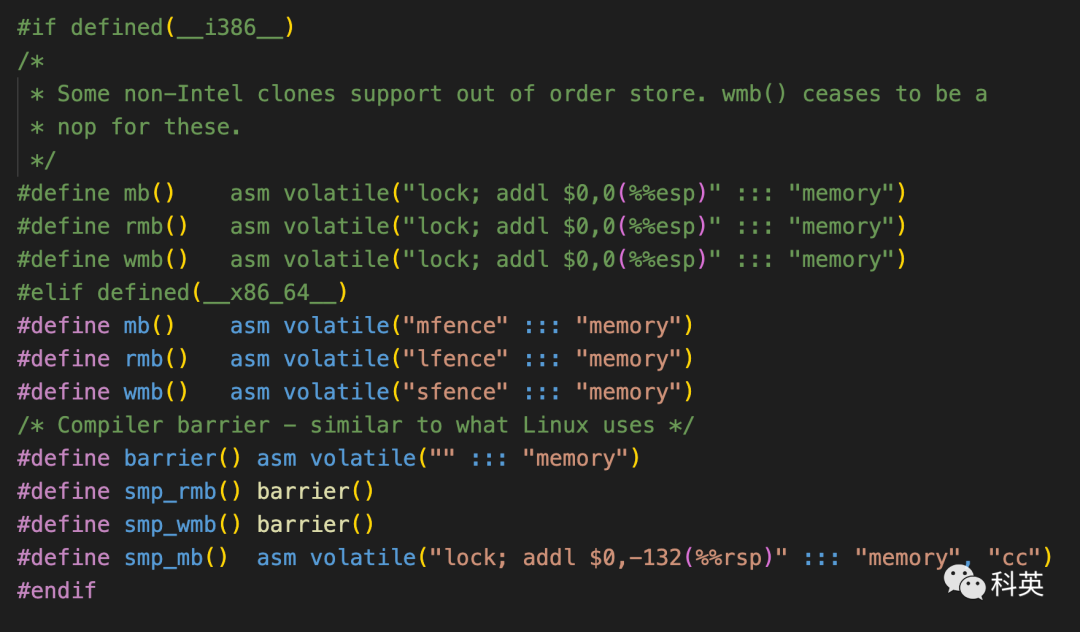
下面的代码是Linux在x86下的内存屏障定义
06
基准测试
6.1关于StoreBuffer的测试
6.1.1测试核心内是否存在StoreBuffer
解析
如果核心0和核心1各有自己的StoreBuffer,会造成上述情况;
核心0将x=1缓存在自己的StoreBuffer里,同样核心1也将y=1缓存在自己的StoreBuffer里,核心0从共享存储中获取y=0;
同理,核心1从共享存储中获取x=0,无法见到x=1;
现代IntelCPU和AMDx86中都有StoreBuffer结构。
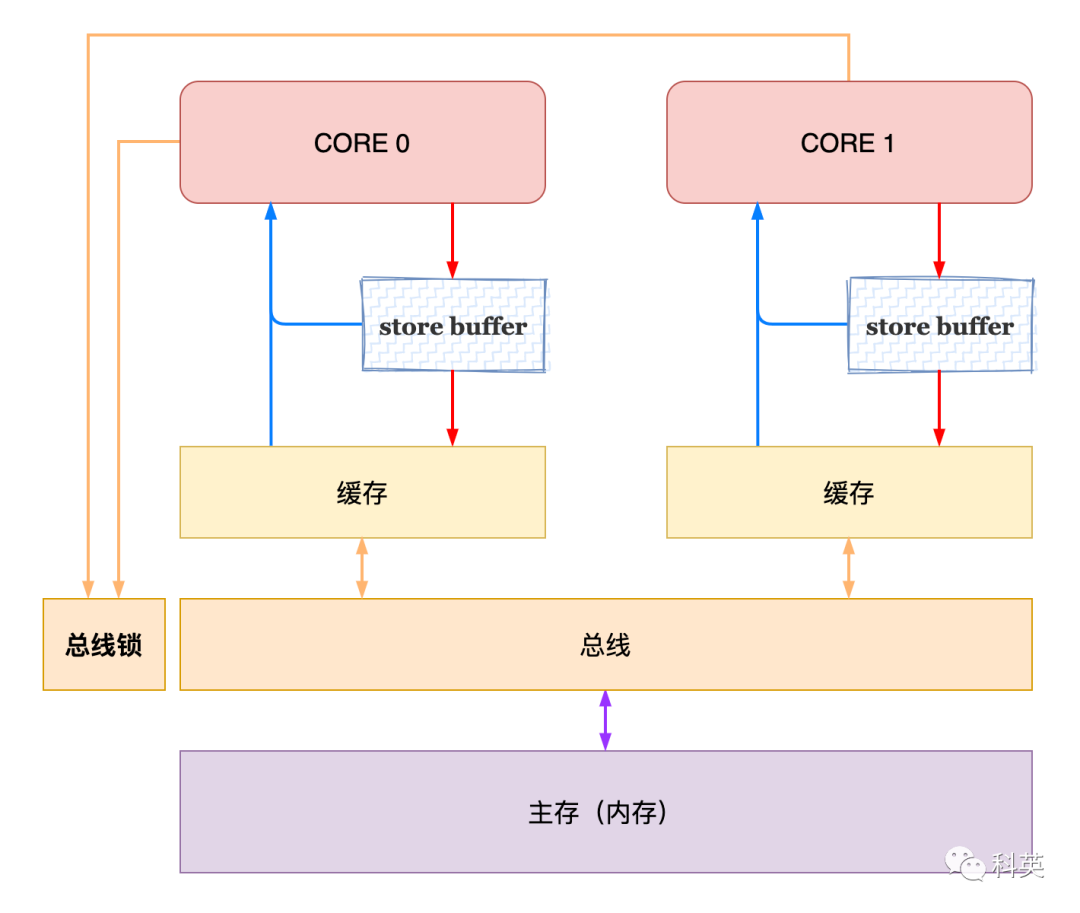
解决
这个测试中从其他核心角度看当前核心的读操作提前了,就是因为有StoreBuffer的存在,导致了从其他核心角度看写操作被延后了;
所以需要引入StoreLoadbarrier来防止读操作提前写操作延后;
在x86中,带lock前缀的指令/XCHG指令/MFENCE,会清空StoreBuffer,使得当前核心之前的写操作立马可以被其他核心看见。
下面有两种解决办法示意图:

在我的电脑上使用smp_mb、mb或rmb可以使上述情况不再出现,而使用barrier或wmb问题还在;
除此之外,还可以使用高级语言的原子变量来解决。
6.1.2测试核心间是否共享StoreBuffer

解析
如果核心0和核心2共享一个StoreBuffer,核心1和核心3共享一个StoreBuffer会出现上述情况;
因为读取时会先去StoreBuffer读取修改,所以核心0执行的x=1会被核心2读取到,故EAX=1;
因为核心1和核心2不共享StoreBuffer,核心1的y=1操作缓存在自己和核心3的共享StoreBuffer中,所以EBX=0;
核心3的ECX=1和EDX=0与上述同理。
总结
实际上,上述现象不允许在任何CPU上观察到,在我的电脑上没有出现;
本例子违反了共享存储一致性,刷到共享存储的数据一定被所有核心可见,并且是一致的。
6.1.3测试StoreForwarding(转发)是否生效

解析
如果核心0和核心1有各自的StoreBuffer;
核心0将x=1缓存在自己的StoreBuffer中,并且根据StoreForwarding原则,核心0读取x到EAX的时候会读取自己的StoreBuffer(中x=1),故EAX=1;
同理,核心1也会缓存自己的写操作,即缓存y=2和x=2到自己的StoreBuffer,因此y=2这个操作不会被核心0观察到,核心0从共享存储中读到y=0,故EBX=0;
总结
出现上述情况就说明核心存在StoreBuffer,并且有转发功能;
在我的电脑(i7)上可以出现上述现象;
其实还有一个更直接的测试用例,如下:

6.2测试CPU是否乱序执行
6.2.1测试:StoreStore乱序

解析
在x86-TSO上,从核心1的角度看核心0,x和y的写入顺序不能颠倒;
因为写操作会按照FIFO的规则进入StoreBuffer,并且按照FIFO的顺序刷入共享存储,所以写操作无法重排序;
所以x=1先入StoreBuffer队列,接着y=1入;
接着x=1先刷入缓存和内存,y=1后刷入;
所以,如果EAX读到1的话,那么EBX一定不是0。
总结
在x86上StoreBuffer是FIFO队列,写操作不允许重排序,无论是从自己还是其他核心角度看都不会发生重排序;
在乱序(out-of-order)CPU上,比如Arm上可能发生StoreStore重排序,所以需要StoreStorebarrier;
6.2.2测试:LoadStore乱序

解析
在x86-TSO上,如果EAX=1,那么说明x=1操作已经从StoreBuffer中刷入到共享存储,并且优先EAX=x执行;
由于x86-TSO的读操纵不能延后,所以EBX=y的操作在x=1之前执行;
同理,EAX=x这个读操作也不能延后到y=1之后执行;
所以EBX=y先于x=1,x=1先于EAX=x,EAX=x先于y=1,所以EBX不可能等于1;
总结
在x86上读操作不能延后,但是可以提前(9.1.1中就是读提前了);
在乱序(out-of-order)CPU上,因为等待写指令可以绕过读指令,比如Arm上可能发生LoadStore重排序,所以需要LoadStorebarrier;
6.3测试n5/n4b:两个核心同时修改同一个变量
6.3.1测试:n5

解析
假如核心0和核心1都有自己的StoreBuffer;
如果EAX=2,那么说明核心1的StoreBuffer中x=2已经刷到了共享存储,那么x=2必然在x=1和EAX=x之间执行,因为EAX会优先读取StoreBuffer中的x,既然EAX=2,说明核心0的StoreBuffer中的x=1已经刷到了共享存储,并且在x=2之前执行的;
EBX会优先读取核心1中的StoreBuffer,所以EBX不可能等于1;
总结
n5实际上不应该在任何CPU上观察到。
6.3.2测试:n4b

解析
假如核心0和核心1都有自己的StoreBuffer;
如果EAX=2,说明核心1的x=2操作已经刷到共享存储,并被核心0观察到,所以x=2先于EAX=x执行;
在x86上读操作不会延后,即EX=x和x=2不会重排,故EBX=x先于EAX=x执行,更先于x=1执行,所以EBX不可能等于1;
总结
n4b实际上不应该在任何CPU上观察到。
6.4测试:写操作的可见性是否传递(如果A能看到B的动作,B能看到C的动作,那么A是否能看到C的动作)

解析
在x86-TSO上,对于核心1,如果EAX=1,那么说明核心1已经见到了核心0的动作;
对于核心2,EBX=1,说明核心2已经见到了核心1的动作,又根据之前的x86-TSO上读操作不能延后,EAX=x不能延迟到y=1之后,所以核心2必能见到核心0的动作,所以ECX=x不能为0。
总结
在x86-TSO上写操作的可见性是传递的;
在乱序(out-of-order)CPU上,写写和读写都是乱序,就不可能保证写的传递性了;
07
CAS原理
比较并交换(compareandswap,CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
下面代码是使用CAS的一个例子(无锁队列Pop函数)
templatetypenameTboolAtomQueueT::Pop(Tv){uint64_ttail=tail_;if(tail==head_||!valid_[tail])returnfalse;if(!__sync_bool_compare_and_swap(tail_,tail,(tail+1)mod_))returnfalse;v=std::move(data_[tail]);valid_[tail]=0;returntrue;}在使用上,通常会记录下某块内存中的旧值,通过对旧值进行一系列的操作后得到新值,然后通过CAS操作将新值与旧值进行交换。
如果这块内存的值在这期间内没被修改过,则旧值会与内存中的数据相同,这时CAS操作将会成功执行,使内存中的数据变为新值。
如果内存中的值在这期间内被修改过,则一般来说旧值会与内存中的数据不同,这时CAS操作将会失败,新值将不会被写入内存。
7.1应用
在应用中CAS可以用于实现无锁数据结构,常见的有无锁队列(先入先出)以及无锁栈(先入后出)。对于可在任意位置插入数据的链表以及双向链表,实现无锁操作的难度较大。
7.2ABA问题
ABA问题是无锁结构实现中常见的一种问题,可基本表述为:
线程P1读取了一个数值A;
P1被挂起(时间片耗尽、中断等),线程P2开始执行;
P2修改数值A为数值B,然后又修改回A;
P1被唤醒,比较后发现数值A没有变化,程序继续执行。
对于P1来说,数值A未发生过改变,但实际上A已经被变化过了,继续使用可能会出现问题。在CAS操作中,由于比较的多是指针,这个问题将会变得更加严重。试想如下情况:

图12
有一个栈(先入后出)中有top和NodeA,NodeA目前位于栈顶,top指针指向A。现在有一个线程P1想要pop一个节点,因此按照如下无锁操作进行
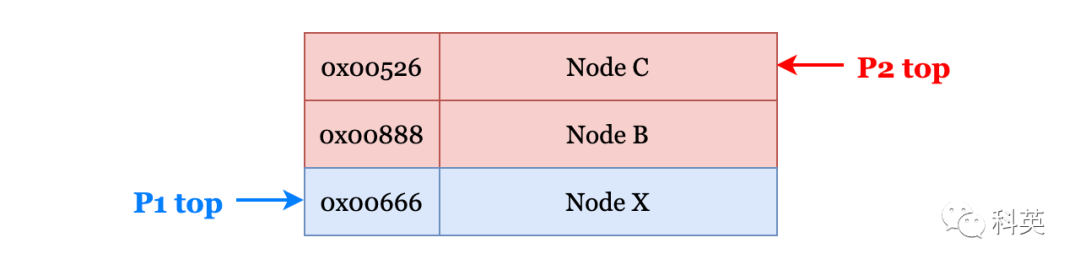
pop(){do{ptr=top;//ptr=top=NodeAnext_ptr=top-next;//next_ptr=NodeX}while(CAS(top,ptr,next_ptr)!=true);returnptr;}而线程P2在P1执行CAS操作之前把它打断了,并对栈进行了一系列的pop和push操作,使栈变为如下结构:

图13
线程P2首先pop出NodeA,之后又push了两个NodeB和C,由于内存管理机制中广泛使用的内存重用机制,导致NodeC的地址与之前的NodeA一致。
这时P1又开始继续运行,在执行CAS操作时,由于top依旧指向的是NodeA的地址(实际上已经变为NodeC),因此将top的值修改为了NodeX,这时栈结构如下:

图14
经过CAS操作后,top指针错误地指向了NodeX而不是NodeB。
简单的解决办法是采用DCAS(双长度CAS),一个CAS长度保存原始有效数据,另一个CAS长度保存累计变化的次数,第一个CAS可能出现ABA问题,但是第二个CAS极难出现ABA问题。
7.3实现
CAS操作基于CPU提供的原子操作指令实现。对于IntelX86处理器,可通过在汇编指令前增加lock前缀来锁定系统总线,使系统总线在汇编指令执行时无法访问相应的内存地址。而各个编译器根据这个特点实现了各自的原子操作函数。
C语言,C11的头文件。由GNU提供了对应的__sync系列函数完成原子操作。
C++11,STL提供了atomic系列函数。
JAVA,提供了compareAndSwap系列函数。
C#,通过Interlocked方法实现。
Go,通过import"sync/atomic"包实现。
Windows,通过WindowsAPI实现了InterlockedCompareExchangeXYZ系列函数。
08
原子操作
程序代码最终都会被翻译为CPU指令,一条最简单的加减法语句都会被翻译成几条指令执行;为了避免语句在CPU这一层级上的指令交叉带来的不可预知行为,在多线程程序设计时必须通过一些方式来进行规范,最常见的做法就是引入互斥锁,但互斥锁是操作系统这一层级的,最终映射到CPU上也是一堆指令,是指令就必然会带来额外的开销。
既然CPU指令是多线程不可再分的最小单元,那我们如果有办法将代码语句和指令对应起来,不就不需要引入互斥锁从而提高性能了吗?而这个对应关系就是所谓的原子操作;在C++11的atomic中有两种做法:
常用类型,长度等于1、2、4和8字节的整形数据,有相应的CPU层级的对应,这就是一个标准的lock-free类型;
大数据类型,结构体等非常用类型数据,采用互斥锁模拟,比如说对于一个atomicT类型,我们可以给他附带一个mutex,操作时lock/unlock一下,这种在多线程下进行访问,必然会导致线程阻塞;
可以通过is_lock_free函数,判断一个atomic是否是lock-free类型。
原子操作有三类:
读:在读取的过程中,读取位置的内容不会发生任何变动。
写:在写入的过程中,其他执行线程不会看到部分写入的结果。
读‐修改‐写:读取内存、修改数值、然后写回内存,整个操作的过程中间不会有其他写入操作插入,其他执行线程不会看到部分写入的结果。
8.1自旋锁使用原子操作模拟互斥锁的行为就是自旋锁,互斥锁状态是由操作系统控制的,自旋锁的状态是程序员自己控制的,常用的自旋锁模型有:
TAS,Test-and-set,有且只有atomic_flag类型与之对应;
CAS,Compare-and-swap,对应atomic的compare_exchange_strong和compare_exchange_weak,这两个版本的区别是:
weak版本如果数据符合条件被修改,其也可能返回false,就好像不符合修改状态一致;
strong版本不会有这个问题,但在某些平台上strong版本比Weak版本慢(在x86平台他们之间没有任何性能差距);绝大多数情况下,优先选择使用strong版本;
LOCK时自旋锁是自己轮询状态,如果不引入中断机制,会有大量计算资源浪费到轮询本身上;常用的做法是使用yield切换到其他线程执行,或直接使用sleep暂停当前线程.
8.2C++内存模型
C++11原子操作的很多函数都有个std::memory_order参数,这个参数就是这里所说的内存模型,对应缓存一致性模型,其作用是对同一时间的读写操作进行排序,一共定义了6种类型如下:
memory_order_relaxed:松散内存序,只用来保证对原子对象的操作是原子的,在不需要保证顺序时使用;
memory_order_release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见;通常与memory_order_acquire或memory_order_consume配对使用;
memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见;
memory_order_consume:同memory_order_acquire类似,区别是它仅对依赖于该原子变量操作涉及的对象,比如这个操作发生在原子变量a上,而s=a+b;那s依赖于a,但b不依赖于a;当然这里也有循环依赖的问题,例如:t=s+1,因为s依赖于a,那t其实也是依赖于a的;在大多数平台上,这只会影响编译器的优化;不建议使用;
memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见;
memory_order_seq_cst:顺序一致性语义,对于读操作相当于获得,对于写操作相当于释放,对于读‐修改‐写操作相当于获得释放,是所有原子操作的默认内存序,并且会对所有使用此模型的原子操作建立一个全局顺序,保证了多个原子变量的操作在所有线程里观察到的操作顺序相同,当然它是最慢的同步模型。
在不同的CPU架构上,这些模型的具体实现方式可能不同,但是C++11帮你屏蔽了内部细节,不用考虑内存屏障,只要符合上面的使用规则,就能得到想要的效果。可能有时使用的模型粒度比较大,会损耗性能,当然还是使用各平台底层的内存屏障粒度更准确,效率也会更高,对程序员的功底要求也高。
8.3C++volatile
这个关键字仅仅保证数据只在内存中读写,直接操作它既不能保证操作是原子的,也不能通用地达到内存同步的效果;
由于volatile不能在多处理器的环境下确保多个线程能看到同样顺序的数据变化,在今天的通用应用程序中,不应该再看到volatile的出现。
09
无锁队列
本节是CPU缓存一致性的实战部分,通过运用前面的理论知识实现一个无锁队列,达到学以致用的目的。
下面是我采用CAS实现了一个多生产者多消费者无锁队列,设计参考Disruptor,最高可达660万QPS(单生产者单消费者)和160万QPS(10个生产者10个消费者)。
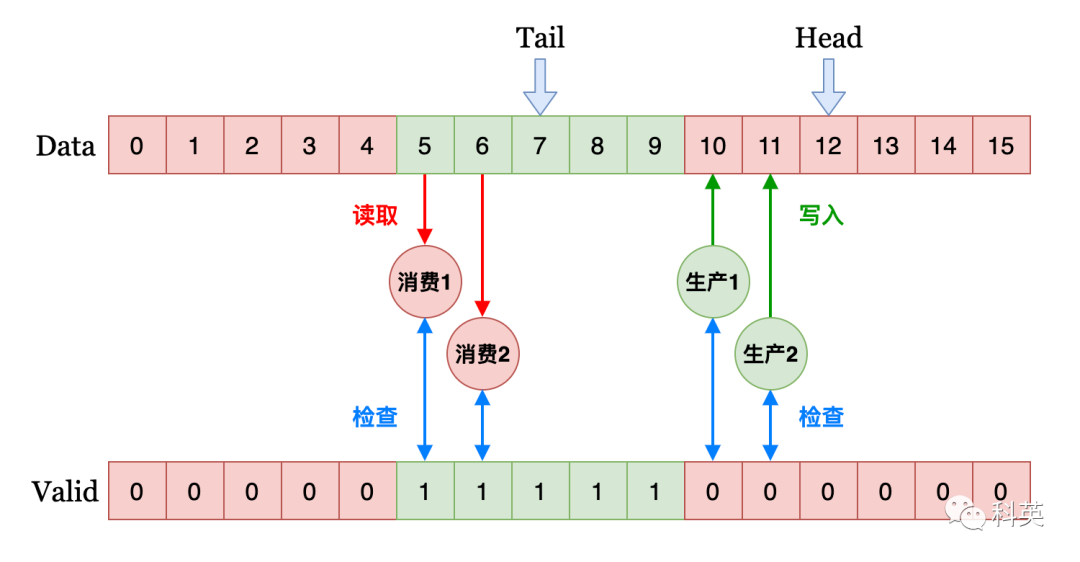
9.1设计思路
1、如图15,使用2个环形数组,数组元素均非原子变量,一个存储T范型数据(一般为指针),另一个是可用性检查数组(uint8_t)。Head是所有生产者的竞争标记,Tail是所有消费者的竞争标记。红色区表示待生产位置,绿色区表示待消费位置。
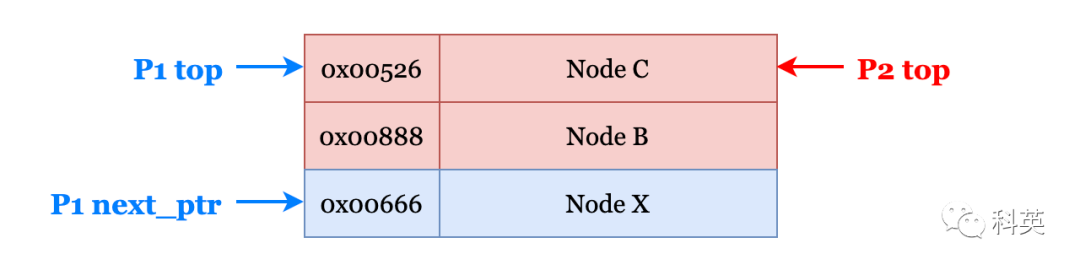
图15
2、生产者们通过CAS来竞争和移动Head,抢到Head的生产者,先将Head加1,再生产原Head位置的数据;同样的消费者们通过CAS来竞争和移动Tail,抢到Tail的消费者,先将Tail加1,再消费原Tail位置的数据。
9.2实现细节
下面多生产者多消费者无锁队列的代码是在x86-64(x86-TSO)平台上编写和测试的。
9.2.1AtomQueue类模板定义
templatetypenameTclassAtomQueue{public:AtomQueue(uint64_tsize);~AtomQueue();boolPush(constTv);boolPop(Tv);private:uint64_tP0[8];//频繁变化数据,避免伪共享,采用Paddinguint64_thead_;//生产者标记,表示生产到这个位置,但还没有生产该位置uint64_tP1[8];uint64_ttail_;//消费者标记,表示消费到这个位置,但还没有消费该位置uint64_tP2[8];uint64_tsize_;//数组最大容量,必须满足2^Nintmod_;//取模%-减少2nsT*data_;//环形数据数组uint8_t*valid_;//环形可用数组,与数据数组大小一致};细心的你会看到head_和tail_还有后面的变量中加添加了无意义的字段P0、P1和P2,因为head_和tail_频繁变化,目的是防止出现前面讲过的伪共享导致性能下降问题。
9.2.2构造函数与析构函数
templatetypenameTAtomQueueT::AtomQueue(uint64_tsize):size_(size1),head_(0),tail_(0){if((size_(size_-1))){printf("AtomQueue::size_mustbe2^N!!!\n");exit(0);}mod_=size_-1;data_=newT[size_];valid_=newuint8_t[size_];std::memset(valid_,0,sizeof(valid_));}
templatetypenameTAtomQueueT::~AtomQueue(){delete[]data_;delete[]valid_;}构造函数中强制传入的队列大小(size)必须为2的幂数,目的是想用而不是%取模,因为比%快2ns,最求极致性能。
9.2.3生产者调用的Push函数和消费者调用的Pop函数
templatetypenameTboolAtomQueueT::Push(constTv){uint64_thead=head_,tail=tail_;if(tail=head?tail+size_=head+1:tail=head+1)returnfalse;if(valid_[head])returnfalse;if(!__sync_bool_compare_and_swap(head_,head,(head+1)mod_))returnfalse;data_[head]=v;valid_[head]=1;returntrue;}
templatetypenameTboolAtomQueueT::Pop(Tv){uint64_ttail=tail_;if(tail==head_||!valid_[tail])returnfalse;if(!__sync_bool_compare_and_swap(tail_,tail,(tail+1)mod_))returnfalse;v=std::move(data_[tail]);valid_[tail]=0;returntrue;}分析一下上述Push和Pop函数中读写操作是否需要增加内存屏障,读写操作可以抽象描述如下表格:
在读写操作乱序的CPU上可以出现上述情况,会导出线Bug,解释一下:
当刚初始化的队列,队列还是空的,这时核心0执行Push函数,同时核心1执行Pop函数;
Push里的条件(tail=head?tail+size_=head+1:tail=head+1)为true,表示队列已经满了,所以生产失败,其实队列还是空的;
Pop里的条件(tail==head_||!valid_[tail])为false,表示队列有数据,并且消费tail位置数据,实际上tail位置还没数据;
导致生产和消费都发生了错误。
解决办法是添加读写屏障(LoadStorebarrier),如下表格:
在Arm等乱序执行的平台上可以解决问题;幸好x86-TSO平台上读操作不能延后,也就不需要读写屏障,手动加了也是空操作(no-op)。
通过执行反汇编命令()得到Push中下面代码的汇编代码。
if(!__sync_bool_compare_and_swap(tail_,tail,(tail+1)mod_))400a61:488b45f8mov-0x8(%rbp),%rax400a65:488d5001lea0x1(%rax),%rdx400a69:488b45e8mov-0x18(%rbp),%rax400a6d:8b80d8000000mov0xd8(%rax),%eax400a73:4898cltq400a75:4889d1mov%rdx,%rcx400a78:4821c1and%rax,%rcx400a7b:488b45e8mov-0x18(%rbp),%rax400a7f:488d9088000000lea0x88(%rax),%rdx400a86:488b45f8mov-0x8(%rbp),%rax400a8a:f0480fb10alockcmpxchg%rcx,(%rdx)400a8f:0f94c0sete%al400a92:83f001xor$0x1,%eax400a95:84c0test%al,%al400a97:7407je400aa0_ZN9AtomQueueIiE3PopERi+0x8c
returnfalse;400a99:b800000000mov$0x0,%eax400a9e:eb40jmp400ae0_ZN9AtomQueueIiE3PopERi+0xcc
发现__sync_bool_compare_and_swap函数对应的汇编代码为:
400a8a:f0480fb10alockcmpxchg%rcx,(%rdx)
是带lock前缀的命令,前面讲过,在x86-TSO上,带有lock前缀的命令具有刷新StoreBuffer的功能,也就是head_和tail_的修改都能及时被其他核心观察到,可以做到及时生产和消费。
10
参考资料
AlderLake-维基百科,自由的百科全书
CPUCache:访存速度是如何大幅提升的?
MESI协议-维基百科,自由的百科全书
MESI协议:多核CPU是如何同步高速缓存的?
内存模型:有了MESI为什么还需要内存屏障?
MESIF协议-维基百科,自由的百科全书
MOESI协议-维基百科,自由的百科全书
为什么在x86架构下只有StoreLoad屏障是有效指令?
TheJSR-133CookbookforCompilerWriters
TheJSR-133CookbookforCompilerWriters[译]
x86-TSO:ARigorousandUsableProgrammer’sModelforx86Multiprocessors
从Java内存模型看内部细节
比较并交换-维基百科,自由的百科全书
C++11原子操作与无锁编程
内存模型和atomic:理解并发的复杂性
x86-TSO:适用于x86体系架构并发编程的内存模型
结束语
OMG,竟然写了这么多,头一次!终于把CPU缓存、内存屏障、原子操作以及无锁队列一口气梳理完了。期间查阅大量资料,这里特地感谢一下参考资料中的作者,让我学到了很多知识;期间也写了很多测试代码来验证理论,避免误人子弟,尽量做到有理有据。由于作者水平有限,本文错漏缺点在所难免,希望读者批评指正。
本文链接:https://goko.jsntrg.cn/329460698060.html