SQLSERVER 的复合索引和包含索引到底有啥区别?


一:背景1.讲故事在SQLSERVER中有非常多的索引,比如:聚集索引,非聚集索引,唯一索引,复合索引,Include索引,交叉索引,连接索引,奇葩索引等等,当索引多了之后很容易傻傻的分不清,比如:复......
在SQLSERVER中有非常多的索引,比如:聚集索引,非聚集索引,唯一索引,复合索引,Include索引,交叉索引,连接索引,奇葩索引等等,当索引多了之后很容易傻傻的分不清,比如:复合索引和Include索引,但又在真实场景中用的特别多,本篇我们就从底层数据页层面厘清一下。
二:到底有什么区别1.这些索引解决了什么问题说区别之前,一定要知道它们大概解决了什么问题?这里我就从索引覆盖角度来展开吧,为了方便讲述,先上一个测试sql:
IF(OBJECT_ID('t')ISNOTNULL)DROPTABLEt;CREATETABLEt(aINTIDENTITY,bCHAR(6),cCHAR(10)DEFAULT'aaaaaaaaaa')SETNOCOUNTONDECLARE@numINTSET@num=10000WHILE(@num90000)BEGININSERTINTOt(b)VALUES('b'+CAST(@numASCHAR(5)))SET@num=@num+1ENDCREATECLUSTEREDINDEXidx_aONt(a)CREATEINDEXidx_bONt(b)SELECT*FROMt;
代码非常简单,在t表中创建三个列,插入8w条数据,然后创建两个索引,接下来做一个查询获取b,c列。
SETSTATISTICSIOONSETSTATISTICSTIMEONSELECTb,cFROMtWHEREbIN('b10000','b20000','b30000','b40000','b50000','b70000','b80000','b90000')SETSTATISTICSIOOFFSETSTATISTICSTIMEOFF输出如下:
表“t”。扫描计数8,逻辑读取次数30,物理读取次数0,页面服务器读取次数0,预读读取次数0,页面服务器预读读取次数0,LOb逻辑读取次数0,LOB逻辑读取次数0,LOB页面服务器读取次数0,LOB预读读取次数0,LOB页面服务器预读读取次数0。SQLServer执行时间:CPU时间=0毫秒,占用时间=134毫秒。SQLServer执行时间:CPU时间=0毫秒,占用时间=0毫秒。Completiontime:2023-01-06T08:47:45.2364473+08:00
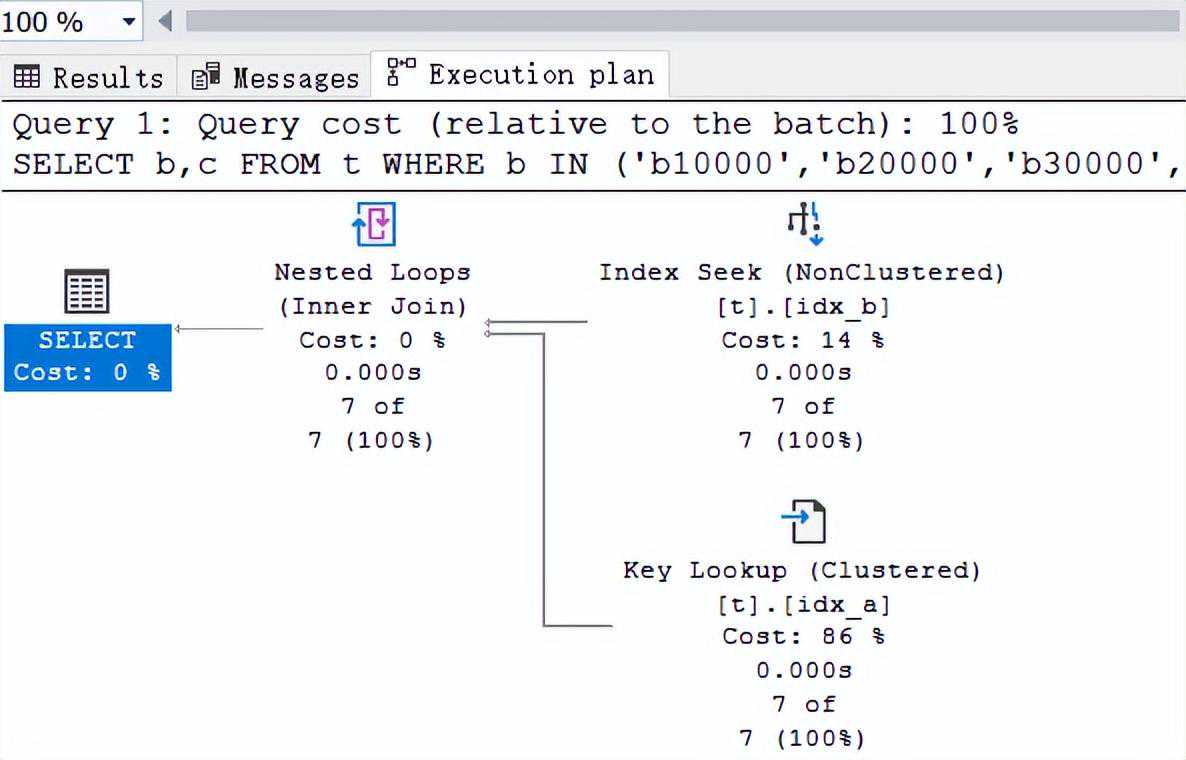
从执行计划看,这是一个经典的书签查找,这种查找返回的行数越多性能越差,在索引优化时一般都会规避掉这种情况,我们也看到了逻辑读取次数有30次,那能不能再小一点呢?
为了解决这个问题,干脆把c列也放到索引中去达到索引覆盖的效果,这就需要用到复合索引了,参考sql如下:
CREATEINDEXidx_complexONt(b,c)
再次查询输出如下:
SQLServer分析和编译时间:CPU时间=0毫秒,占用时间=0毫秒。表“t”。扫描计数8,逻辑读取次数24,物理读取次数0,页面服务器读取次数0,预读读取次数0,页面服务器预读读取次数0,LOb逻辑读取次数0,LOB逻辑读取次数0,LOB页面服务器读取次数0,LOB预读读取次数0,LOB页面服务器预读读取次数0。SQLServer执行时间:CPU时间=0毫秒,占用时间=96毫秒。SQLServer执行时间:CPU时间=0毫秒,占用时间=0毫秒。Completiontime:2023-01-06T08:53:56.9688921+08:00

从执行计划来看,这次没有走书签查找而是索引查找,并且逻辑读也降到了24次,这是一个好的优化。
相信有些朋友也知道用Include索引也能达到这个效果,接下来试着把复合索引给删了增加一个Include索引,代码如下:
DROPINDEXidx_;CREATEINDEXidx_includeONt(b)INCLUDE(c)
再次查询输出如下:
表“t”。扫描计数8,逻辑读取次数16,物理读取次数0,页面服务器读取次数0,预读读取次数0,页面服务器预读读取次数0,LOb逻辑读取次数0,LOB逻辑读取次数0,LOB页面服务器读取次数0,LOB预读读取次数0,LOB页面服务器预读读取次数0。SQLServer执行时间:CPU时间=0毫秒,占用时间=73毫秒。SQLServer执行时间:CPU时间=0毫秒,占用时间=0毫秒。Completiontime:2023-01-06T08:58:18.1122561+08:00

从执行计划来看也是走的非聚集索引,而且逻辑读再次降到了16次,相比原始的书签查找已经优化了50%,这是一个巨大的性能提升不是。
到这里其实有一个问题,两种优化走的都是非聚集索引,从逻辑读次数看貌似Include索引更好一些,为什么会这样呢?这就涉及到了底层存储,接下来一起扒一下。
2.存储原理研究研究它们的不同点,最彻底的方式就是从底层存储出发,首先我们观察下复合索引的底层存储是什么样的,可以用DBCC命令。
DBCCTRACEON(3604)DBCCIND(MyTestDB,t,-1)

从IndexLevel=2来看这个复合索引构成的B树已经达到了二层,接下来我们查一下368号数据页内容。
DBCCPAGE(MyTestDB,1,368,2)
输出如下:
PAGE:(1:368)MemoryDump@0x000000F55557F555578000:0102000200000000001b0000000000..000000F555578014:000002003e010000601f9c007001000001000000.`:f8000000e0680000f50100000000000000000000..h..000000F55557803C:0000000001000000000000000000000000000000..000000F555578050:0000000000000000000000000000000016623130..b10000000F555578064:3030306161616161616161616101000000380500000.000000F555578078:0001000833363616161.b83616aaaaaaa000000F55557808C:616161911:Row-Offset1(0x1)-126(0x7e)0(0x0)-96(0x60)DBCC执行完毕。如果DBCC输出了错误信息,请与系统管理员联系。
根据下面的Slot个数可以知道这个分支节点数据页只有2条记录,分别为:(b10000,aaaaaaaaaa,0x01),(b83616,aaaaaaaaaa,0x011f91),这里说明一下最后的01和0x011f91是主键key,接下来找个叶子节点,比如:1632号索引页。
PAGE:(1:1632)MemoryDump@0x000000F55557F555578050:0000000000000000000000000000000016623135..b15000000F555578064:32383761616161616161616161:16623616161616161616161:0006161616161616161..b15289aaaaaaaaa000000F5555780A0:61aa01662361616161a..b15290aaaaa000000F5555780B4:6161616161ab016623aaaaa..b15291a000000F5555780C8:616161616161616161ac016623135aaaaaaaaa..b15000000F5555780DC:32393261616161616161616161:16623616161616161616161:0006161616161616161..b15294aaaaaaaaa000000F555578118:61af01662361616161a..b15295aaaaa000000F55557812C:6161616161b0016623aaaaa..b15296a000000F555578140:616161616161616161b1016623135aaaaaaaaa..b15
从叶子节点上看,也是(b,c,key)的布局模式,这时候脑子里就有了一张图。
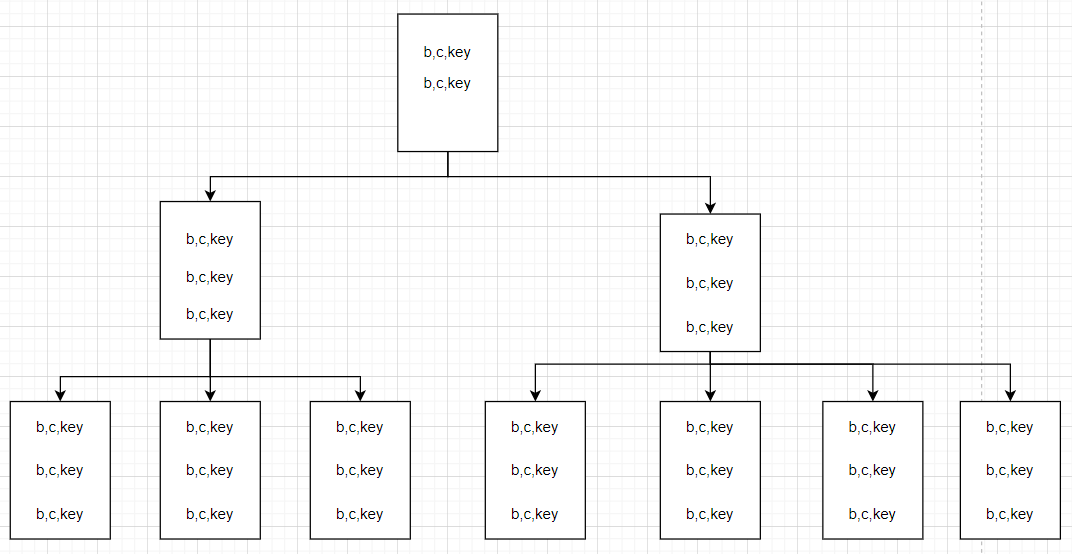
用同样的方式观察下Include索引,发现IndexLevel=1,说明只有一层。

再用DBCC观察下分支节点的布局。
PAGE:(1:1696)MemoryDump@0x000000F554F7F554F78000:0102000100820001000000000000110000000000..000000F554F78014:00000601420100001.000000F554F78028:0.9..000000F554F7803C:f01efa000000000000000000000000..000000F554F78050:0000000000000000000000000000000016623130..b10000000F554F78064:3030300100000088030000010003000016623130000..b10000000F554F78078:333:3632326:393333a6030000b2030000010003000016623131933..b11
从输出看并没有记录列c的值,就是那烦人的aaaaaaaaaa,然后再抽个叶子节点看看,比如:1218号索引页。
PAGE:(1:1218)MemoryDump@0x000000F554F7F554F78000:0102000004020001c10500c3040000..000000F554F78014:01003701420100000a00881dc20000..7.B000000F554F78028:0f01000000310000030000000000000000000000..1..000000F554F7803C::0000000000000000000000000000000016623833..b83000000F554F78064:313235:16623833313236:610833313237:61616161610833313238:6161616161616161610833313239:1:313330
在叶子节点中我们终于看到了aaaaaaaaaa,其实想一想肯定是有的,不然怎么做索引覆盖呢?有了这些信息,脑子中又有了一张图。
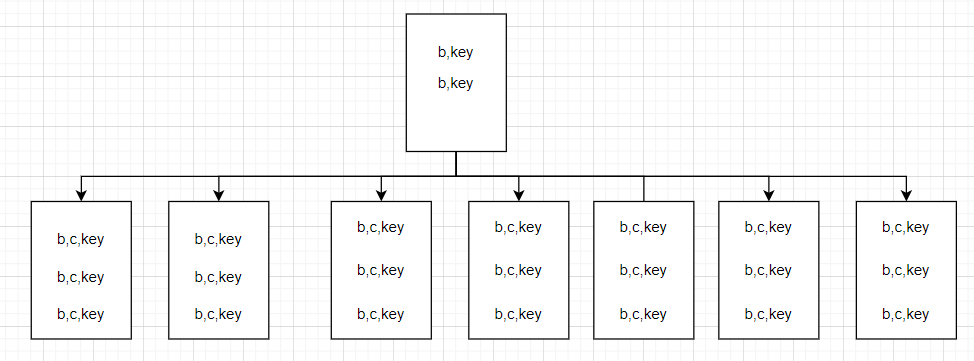
从图中可以看出,Include索引的分支节点是不包含c列的,这个列只会保存在叶子节点中,再结合树的高度来看就能解释为什么Include索引的逻辑读要少于复合索引。
三:总结总的来说复合索引和Include索引各有利弊吧,前者会让索引页的行数据更大,导致索引页更多,也就会占用更多的存储空间,更多的逻辑读,索引维护开销也更大,而后者只会将Include列保存在叶子节点,不参与索引计算,相对来说占用的索引页空间更小。
在查询方面,复合索引能达到的索引覆盖场景远大于单列索引,而且在过滤,排序场景下也能发挥奇效,所以还是根据你的读写比例做一个取舍吧。
本文链接:https://goko.jsntrg.cn/618610558182.html