端到端的介绍从CLIP到Sora


这是以前的我写的多模态系列,进行的重整理,去除了调侃的话和描述不清楚的地方,相当于重写了一遍,也算是万字长文了。个人感觉就算不是全网最细也能排进前10了,我尽量往简单了写,想入门多模态的各位可以无脑刷......
这是以前的我写的多模态系列,进行的重整理,去除了调侃的话和描述不清楚的地方,相当于重写了一遍,也算是万字长文了。个人感觉就算不是全网最细也能排进前10了,我尽量往简单了写,想入门多模态的各位可以无脑刷。
第5章多模态架构MLLM讲解MLLM(MultimodalLargeLanguageModels)即多模态的大语言模型,顾名思义,这个还是以大语言模型为基础的
如何说明一个模型是多模呢?主要是2点:
1-Encoder,decoder的多模
2-多模融合
5.1FLIP从一个简单的多模态CLIP讲起,CLIP也是OPENAI的模型,现在也被广泛的应用于各种多模态的业务场景里,本身是开源的,又是挺重要的分类器,目前开源的多模态模型或多或少都用了它的代码和概念首先看它是怎么实现的,如图5-1
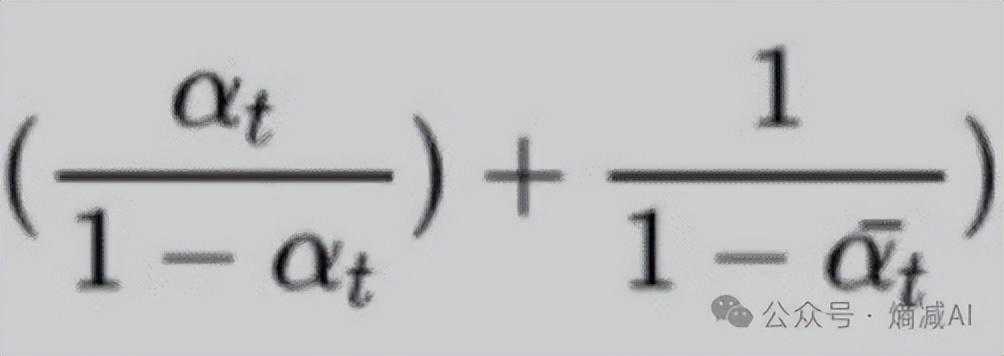
图5-1CLIP的概念
CLIP的训练方式也可以被称为对比学习,首先设计一个矩阵,矩阵的行方向,是由一个Text-encoder来实现对于文本的embedding,它针对训练数据中的图片的描述给encoding成向量,Text-Encoder我们可以拿任何的Text-Transformer来实现。
相对应的,有一系列图片,这些图片和上面的图片描述是对应的,同时有一个image的的encoder,这个encoder也会把图片的高维数据,压缩成一个向量,Image-Encoder可以是ResNet,也可以是VGG,ViT都可以。
如图5-1所示,第一个文本T1和一堆图片I1到IN的向量做内积,最大的那个就是I1T1,第二个也是如此,I2T2,一直到InTn,相乘的得到一个矩阵的对角线,这个对角线就是最大值的一个集合。
既然要训练,那目标函数F(I,T)是什么呢?很显然它的目标就是最大化正样本的相似度,其他的位置全是负样本,要让负样本最小化。
5-2CLIP的推理
在推理的时候,如图5-2所示比如给一个zero-shot就给一只狗的图片,过了imageencoder以后,和上面的text-encoder下来的那个向量做点积。然后直接取最大的那个,就能得到一句话"aphotoofadog",就完成了一个简单的图片分类的任务。
CLIP和传统的什么resnet的训练方式不一样,不用定义正负样本,只需要标准文本图像对,正负样本是在batchsize里面随机得到的。
训CLIP的话,batchsize挺重要的:
第一:bacthsize不能太小,因为没有正负样本提前规划,所以如果训练太小的话,对角线跑不出来,比如给了文字,没给够足够的图片,文字知道和描述类似的东西是啥,但是不能理解不类似的东西是啥,那自然训练效果就不好,说白了就会变成隐式负样本的缺失。
第二:batchsize大,但是分类任务设置的太小,比如即使batchsize是100,但是分类任务就2个(猫,狗),有可能你这100个也捞不出来几个负样本,所以训练效果还是不好。
CLIP比传统的分类方式好处在哪呢?
图5-3CLIP和ResNet101对比
如图5-3所示,比如拿真实的水果图片去做训练,然后拿Resnet和CLIP来PK,同样的都是真实水果图片的场景来推理,它俩其实差不多,CLIP也没看出来好。但是,随着图片越来越抽象,ResNet的准确率下滑的就不是简单的线性了,甚至指数的下跌,这就是训练方式不同导致的CLIP显示出来的优势,从另外的角度解读就是,它的泛化能力特别强,支持新类别的拓展。
支持新类别的拓展是什么意思呢?因为它对图片来讲是点积得到的吗,我举个例子,你说“Awomenwalksonastreet”和“Agirlwalksonastreet”,这两句话虽然不一样,但是women和girl的余弦距离本来就没那么大,所以你拿一个girl的图片来让只见过"women"的CLIP分类器来分类,一样能给比较好的完成下游任务。
还一个值得说的就是工程化的能力
如图5-3红框的这两个部分和对角线矩阵是松耦合的,所以意味着完全可以独立离线计算,可以不一起占用算力,在上线的时候两个encoder各自训练好,再开始算对角线就可以了,也能实现算力版的"分时复用"
图5-3算力分时复用
5.2VIT图5-4VIT
我们来看看一下Vit的思路如图5-4,整个网络就是一个普通的Transformer网络,包含了正常的attention层,MLP层,Norm,和LN啥的也都有。
主要区别其实是在Transformer的Encoder前面整了一个线性层,这个线性层是整个网络的核心。
线性层主要作用就是mapping,何为mapping,就是把图片这种和文字不相干的元素也能被处理NLP的网络来进行处理,这就是mapping的含义。
那它具体是怎么做到的?
图5-5Patch+PositionEmbedding
首先它把一幅图比如224*224*3的给切分了,比如切成一堆每块16*16*3的Tensor,(乘3就是RGB通道,这里当彩图处理的),这个Tensor被命名了一个名字叫Patch。切完了以后,每个patch不是16*16吗,但是原图是224*224的,除以16*16就得到了196的patches,所以输入到encoder的seq_number就应该是224*224/16*16=196,如果是彩图,加上RGB,每个patch的tensor形状就是16*16*3=768。
然后这个tensor要做一个shape变成768,这样输入的训练数据就是[batch_size,196*768]这样的一个tensor,这里需要注意的原来这模型刚出来,实际上是个分类任务,所以又加了一个cls的分类字段。也就是197维的seq_number了,真实的输入训练数据是[batch_size,197,768]。
还有一种是不加cls位,然后token算加权,最后让一个MLP去做分类,我们就不介绍了,意思也差不多。
这个Tensor要被送入到线性层,线性层其实就是个编码层。
Tensor进来以后和Transformer一样要加进去位置编码,比如图里画的0-9,原论文是用和GPT一样的绝对编码来做的,通过正弦余弦来表示。编码完还是一样[batch_size,197,768]。
进了Transformer以后过多头self-attention再过MLP,最后唯一区别输出是一个图的分类,不是关于字典的logit。
5.3VAE
VAE的上一任叫AE,就是Auto-encoder
简单说,就是训练两个函数,一个是NNencoder(其实就是个神经网络)用于压缩图片,图片到低维特征的压缩,然后NNdecoder这个函数,来对降过维的低维特征进行反向重现,或者叫解压缩吧。
为什么AE能用要从AE升级到VAE?
图5-6AE
原因就是它第一个压缩网络生成的是固定的值,比如1001,3005,6078,这种固定的值就是容易过拟合,如图5-6所示,要是见过这些数字的,它可以正常解码,如果没见过,它不知道咋解码。
VAE怎么解决了上述问题呢?既然固定的数值容易过拟合,那就用不固定的方式来打破这种拟合。
图5-7VAE
VAE在Encoder时候不生成固定数字了,取而代之的是生成一个分布,通过生成不同的均值μ和方差,得到不同标准的正态分布,然后再采样成可表达的code,最后再输入给NNdecoder,因为压缩的值是根据正态分布采样的,所以即使没见过的,也就能猜差不多,如图5-7所示,找它的分布对应的值域。
5.3DDPM在第一篇我们简单介绍了一下CLIP,第二篇讲了VAE和ViT的部分,从这节课我们开始介绍DiT,引入就是DiffusionTransformer,DiT不是一个模型,它包含了VAEencoder+ViT+DDPM+VAEdecoder,其实最核心的部分就是DDPM,也就是DenoisingDiffusionProbabilisticModels。
就DDPM本身而言各个解决方案都有自己的DDPM方法,它严格说也没那么绝对统一,但是大体思路都是靠diffusion算法来实现的,为了让大家更好理解,本章从Diffusion算法开始讲起。
图5-8Diffusion前向计算
一切从这个经典的图开始讲起。
这个图很好得描述了DDPM或者Diffusion算法的前向工作方式,就是往一个好图里加噪音(符合高斯分布的噪音),有人问,它这么做不是相当于往大米里加沙子吗?
我们先不考虑做这个事情,是否有意义,先把它当成一个数学问题来思考,那请问X2时刻的图像和谁有关呢?按照上图所示,肯定和X1有关,递归过去,X1是和X0有关,所以我们可以列一个式子,Xt=Xt-1+Z(Z就是噪声),基于这个顺序,可以总结出来一条类似马尔科夫链的结构。
第二个问题,这个Z的噪声是不是恒定的,看图就能看出来不是恒定的,因为到最后,如果还是和最开始只加一点噪声来对图像加噪,基本就起不到什么效果,所以这个噪声也是递增的,原论文是0.0001到0.02。
我们来设计一下这个噪音模式,首先设置两个权重,一个是αt,一个是βt,他们之间的关系αt=1-βt,βt就是我刚才提到的0.0001到0.02。
那么,便有图像在Xt时刻:
我们来解读一下这个式子,首先βt(也就是1-αt)因为加噪音的需求,需要满足越来越大,所以αt就会越来越小,那么上式中,加号左边的权重就会越来越小,也就是上个时刻的图片的影响会越来越小,而针对噪音Z1的权重就会越来越大。这也就满足了我们噪音越来加地越多的想法到算法的基础。
那么把这个式子再延伸一下,其实Xt-1时刻我们也可以用这个式子来表达出来。
把Xt-1代入Xt的式子。
这个式子可以继续拆解为一个关键的式子,我们称它为A:
然后有意思的来了,这块注意看,因为Z1和Z2都是符合正态分布的噪声,那么正态分布的东西乘上一个值相当于什么?相当于方差做了改变而已(不是1了)。
Z1和Z2的正态分布:
Z1:
Z2:
又因为符合正态分布的两个分布相加还是得到正态分布。
所以我们把式子A的后两项合并:
这部分式子按着刚才讲的都符合正态分布加法的方法来合并。
第一步:
第二步:
第二步的式子就是把Z1和Z2的正态分布加一起了,得到Z1+2这个分布。
然后把式子A的Xt-2的前面的式子也合并掉,就得到了下面的式子B。
细心的读者可能会把式子B和初始求Xt的式子做对比,我们很容易就发现问题了,如下:
我用X-2去求Xt,就比X-1在加法左端和右端的根号里,多乘一个αt-1,那用Xt-3时刻来算,就是多乘个αt-2,一路累乘上去,(Z那边也就是噪音那边就是累加过去)。
如果是X0呢?
现在得出了上面的式子C,它的数学意义是什么?很好理解,在给定的时刻Xt,只要知道X0(初始图片),就可以求出任意时刻Xt的噪声图应该是啥样子,然后不断得累成α的t,t-1,t-2时刻一直到t-n时刻就了。换句话说,对于扩散模型DDPM来讲,只需要了解初始图片的样子,扩散多少步,就直接能算出来噪声图。
式子C的表达的意思,就是任意时刻的加了噪声的图,理论上都可以由X0时刻的干净的图片,通过当时刻的α的累成和高斯分布的噪声Z累加来求出来(但是其实也就是当时刻的噪声Zt,写成Zt也一样)。
目前给图片加了噪声,现在则要把加过的噪声给去掉,还原成原来的图片。
正向其实还是很简单的,大家自己也可以推,正向训练完了以后,网络主干backbone(Unet或者Transformer),已经学会了一步加噪声(参加上面的公式),但是反向相对比较麻烦。
用一个纯的噪音图片一步还原成干净的图片,怎么考虑,逻辑上都是不可能。
现在换个思路,如果一步不行,我可不可以多次来做这个事情呢?
图5-9多步去噪声
假如有100个时间步的噪声图,现在已知条件是无法求出0步时刻的X,那么有没有可能求出99步时刻的噪声图?
这个思路好像听起来逻辑是通的,贝叶斯公式应该可以解决这个问题,如果直接求,求不出来,但是逆过程可以求(直到Xt-1时刻,可以求出Xt),也能通过贝叶斯把解求出来。
如果知道Xt时刻和X0时刻的条件下,能不能求出Xt-1?显然是不能的。
现在把步骤反过来。等式右边,第一个式子,在知道Xt-1时刻和X0时刻的条件下,能不能求出Xt,这个是可以的(正向肯定是可以的);然后第二个式子,再分别求X0已知的情况下,Xt-1和Xt的分布,这个都是可以求的,所以既然两个式子都可以求,那么自然整个式子也可以求。
至于怎么求,之前列好的式子,我们正好用上了。
针对上面的3个式子进行拆解,正好等于贝叶斯公式的右边3个部分,Z就是多个分类累加,但是还是正态分布,所以统一用Z代替了,因为乘改变了方差(要平方),加改变了均值,所以,只是正态分布的区间就变了而已。
标准正态分布都符合上面的式子,同时标准正态分布里面,乘法就是加法,除法就是减法,那么把这三个式子代入前面的贝叶斯公式即得:
总体思路就是要拆出来以Xt-1为未知项的一个1元2次方差,通过尝试配平
又因为
两个式子对比,其实可以把Xt-1就当成x来看。最后的C是个常数项(先决条件就是Xt和X0都是常数),所以不考虑它了,把上下式一起看,可以能求出来方差,因为αt是已知的,αt的累乘也是已知的。下面式子的倒数就是方差了。
比如把一幅照片看成是一个像素分布,只有方差可以吗?自然是不行的,也要求均值,这个均值μ可以把均值对应的式子代入进去,但是同时,这个式子还有Xt和X0作为条件(虽然是常数,但是是未知项),那么问题来了,X0能被表示吗?显然不能,需要求解方的就是X0,如何求?那么就需要通过Xt来求X0。
根据之前的式子
我们就可以把X0用Xt来表达,通过反复的计算化简,就能得出来我们的均值μ。
这下均值和方差都有了,分布我们也就有了,那不就能求出来解了吗?看似万事俱备,但是好像有个问题,Z如何求?
噪音这东西没法数学求解,那就只能求近似解了,就是拿一个backbone去训练来求噪声Z。
到此,通过贝叶斯来逆向操作一个通过X-1来求Xt的推导过程就完事了,因为我们推导出了最终结果(虽然有一部分是靠模型训练的猜噪声),通过Xt来推理Xt-1的猜想也就可行了,然后一直推,直到推来X0,我们的任务就OK了。
如果我们用Unet做backbone的话,整体的流程大概就是图5-9这样。
图5-9Diffusion流程概图
目前我们已经完成了一个从照片加噪,到去噪重新还原到原图(接近)的前向和后向的逻辑算法的提炼。
现在需要给它一些指令,让它能根据提供的指令来生成图片。
回到项目上来,既然想完成一个文生图的动作,是不是不能光训练图片啊?至少得让网络知道对这些训练图片的理解。
所以我们首先要有个文字的embedding模型,一般来讲StableDiffusion的text-embedding就是CLIP的text-encoder部分。
在具备了文字的encoder以后,还需要一个东西,就是进行图片编码,其实这个和文字严格说没啥区别,只不过它被定义为叫patch,当token看就可以了。
还缺一个Backbone,这个Backbone的作用就是训练时做加噪音,去噪音。推理时纯去噪音的。
至此一个基本的StableDiffusion模型的骨架搭起来了,如图5-10
图5-10StableDiffusion概览图
这个东西能不能工作?可以负责的说肯定可以工作,但是有一些问题,比如:
往Backbone里一直输入1024*1024的图,得有多少算力和显存,来做这个事情。
又比如,把一些图像和一些文字对应起来,那其他的想生成的idea咋办,换句话说过拟合和鲁棒性缺失的风险。
推理速度的压力。
能不能做个2段式的程序?
比如在之前我们讲了VAE就是一种图像对图像的压缩技术。
所以可以这么考虑,先训练出来一对VAE的encoder/decoder,然后让它们先对图片组进行训练。最后就会得到一系列的正态分布。进而,先让VAE去把像素空间PixelSpace,通过encoder给压缩到一个隐空间,或者叫潜在空间LatentSpace,然后对潜在空间的Latent(被编码的code或者小图片)进行加噪,去噪。等推理的时候再由成对的VAE的decoder给解码出来,完成了训练效率和多样性的双重提升!
好,我们现在把VAE给加进来。
图5-11加入Decoder的Diffussion概览图
加进来的网络就长这样子了,文字的encoder部分,我们没有变化,但是图像部分,我们不是输入给网络一个完整的样张,其实是加了噪的latent,实际的训练中,VAE的encoder和decoder可以独立于网络训练完。
下一个问题Backbone用啥,Backbone可以先使用比较通用的Unet。
图5-12Unet
用它原因就是简单,而且这个进出的U字型对称,也特别符合扩散模型从大压缩小,从小扩散大的特点,仅此而已。官方一点的说法就是,稠密预测任务,就像图像分割,图像去噪一样。这些传统的稠密预测任务UNet已经有了很好的呈现,在新任务上自然也就沿用下来了。
这个模式也叫做LatentDiffusion,又叫LDM,也是StableDiffusionSD的最早的组网思路。
5.4DiT图5-13DiT
如图5-13所示,仔细看其实和图5-11没区别,只不过VAE的部分,就是隐空间压缩/解压的部分没画进去而已。
按着图5-13来讲,这次要从下往上看,而且是一个推理的过程:
左边灰色部分是隐空间的输入(加了噪的Latent或者小图,形状是32*32*4)然后经过Patchify,就分成了不同的Patches了,类似NLP里面句子的分词和token化。
然后进入到了DiTBlock,它的扩展图,大家一眼就看能出来了,Transformer
关于条件注入DiT它原始有4种我们着重讲图上的3个,按图中的顺序从左往右:
adaLN-zero:引入额外的MLP层,这个MLP层和所有的归一化LN层都有互操作,这么做的目的是为什么呢?除了回归γ和β之外,还回归维度缩放参数α,这些参数在DiT块内的任何连接之前生效,是为了模仿残差网络中的有益初始化策略,以促进模型的有效训练和优化。(最新的SD3也是用这个,Sora估计也是用)
Cross-attention:将两个embedding拼接起来,然后在transformerblock中插入一个crossattention,将embedding作为crossattention的K和V;要引入的额外计算量最大。
In-contextconditioning:将latent和文字embedding作拼接,类似ViT中的clstoken,实现起来比较简单,不消耗额外算力。
剩下的运算就比较好理解,经过若干层网络输出一个均值和方差,分布出来了,图片也就生成好了。
为什么要用Transformer来替代Unet,有两个原因:
1-Transformer的扩展性和普遍性
2-ScalingLaw
5.5对Sora进行逆向工程上节我们讲了DiT,其实就是基本搭建了Sora骨架了,现在我们要加一些血肉(feature),让它变得活灵活现起来。
ViViT有两种编码模式:
第一种叫Uniformframesampling:
图5-14Uniformframesampling
第二种叫Tubeletembedding:
图5-15Tubeletembedding
如图5-15所示,第二种方式是更3D的,是从输入整体中以时空方式取得不重叠的立方体,将VIT的embedding扩展到3D形式,形状是[W,H,T](W,H,T取实际取值,不是最大值)
图5-16Sora的embedding
其实这东西很好理解,可以理解为语言模型的外推性差不多,因为一个batch进去的sequence就那么多,做不完就要截断。所以输入进去一样分辨率的图片训练,至少能保证放进去的那些图片是被选中的,然后其中的内容,比如人物,景色,尽量居中,或者按着我们的想法在图片上排布。否则就会变成图5-17这样的效果。
图5-17分辨率的问题
答案是就会发生左边这种图的现象,其实以前使用过的大概深有体会,因为它就是用固定分辨率图片来进行训练的。所以当生成别的分辨率就会有对象排布的问题。
图5-18NaViT
NaViT的思想具备通用性,其实不只是对图片,对NLP也一样生效。
简而言之,先看最下面一层,在数据给到网络的时候拿到的就不是一样size的图片(做NLP不是一样长的句子也行),然后进行Patch化,同时在这一步,它就做了dropout为了增加模型的鲁棒性。
然后这3张图片的patches被一个线性层给拉齐到一维的向量,如果定义的向量最长长度太长,还得加点pad。
好玩的来了,虽然被拉到了一个向量里,这里面额外加了2层(实际上是多层,逻辑上2层)mask过的线性层,一个是self-attention层(但是只算QK),一个是pooling层(QKV之前的pooling)。虽然这三个图的patches都在一个向量里,但是因为mask的存在,还是能各算各地,比如算1就mask2和3,然后最终完成QKV的计算,还能保证虽然大家在一个向量里,可是分别计算,没有混乱。
简单说就是Recaptioning大道至简,就是训练一个imagecaptioning模型将原来的textprompt进行优化,生成描述更加详实的文本,本质上是一种NLP思路,现在很多生成一致性人物的论文,也是在优化prompt这个角度进行研究。
例如你说"画个海龟游泳",GPT-4马上给你渲染一下,如图5-19。
图5-19GPT-4recaptioning
Sora的feature基本都介绍全了,现在可以看一下Sora的训练和推理步骤。
先讲前4步(图转载自普林斯顿的TomYen老师):
图5-20Sora-1
1-首先一个trainingvideo到达了,有4帧构成。
2-4个帧被resharp成一个matrix。
3-进入Sora的VE,可以理解成是VAE,好玩的来了,然后完成矩阵乘和Bias(最后一列),这一步做完了直接过一个Relu函数,因为Relu只有正数部分,所以如果是负数的矩阵运算+偏移,最后都会变成0。
这一步的运算逻辑就是Video被编码的patches被压缩成latent的过程。
4-加入噪声进来
图5-21Sora-2
5-这个时候看右边,要操作condition部分了,首先定义跑几步,比如跑3步,那这个step3就用2进制11来表示,然后它和prompt"Soraissky"被encode成的textembedding来做矩阵乘。
6-得到的这个结果要经过一个linermask矩阵(最后一列也是偏移),这一步的目的是要得到Scale和Shift,这个列向量的上半部分[2,-1]是scale部分,下半部分[-1,5]是shift。
7-然后左右变量的cross-attention就开始了,要把左边的被加过噪声的latent和这个scale相乘然后相加shift得到一个加了条件的噪声过的latent。
图5-22Sora-3
8-加了条件的噪声过的latent,然后做QK的矩阵乘。
9-这一步就做pooling了,第8步和第9步和上面描述的NaViT是一样的操作。
10-过FFN(最后一列还是偏移),通过FFN预测出来了噪声,需要注意的是预测出来的是噪声,不是加噪声的latent。
图5-23Sora-4
11-然后把预测的噪声和原始的噪声做对比,求Loss
12-关于推理部分,VAE的encoder-decoder可以独立于DiT训练,所以在训练的时候是不用VE的decoder参与进来的,推理需要考虑进来,这一步就是用加了噪声的Latent减去预测的噪声得到去噪了的Latent
13-拿纯净的lantent去被VAE的decoder解码,解码出来一个matrix,这一步也需要拿Relu把负值给滤掉了
14-和第1步的操作正好是逆操作,把矩阵重新排列成一帧一帧的patches,重组成video。
本文链接:https://goko.jsntrg.cn/406922304119.html