LangChain-Chatchat:基于LangChain和ChatGLM2-6B构建离线知识库


一、前言如果是站在一个中小企业的角度,去选型一款比较符合企业构建本地知识库需求的产品来评估,从以下介绍的开源产品目前的实现效果和未来规划目标来看,个人觉得Quivr从设计上来讲更加符合应用需求,前提是......
如果是站在一个中小企业的角度,去选型一款比较符合企业构建本地知识库需求的产品来评估,从以下介绍的开源产品目前的实现效果和未来规划目标来看,个人觉得Quivr从设计上来讲更加符合应用需求,前提是增加企业已有文档库、数据库纳入知识库的能力,扩展Danswer提高的功能,完善并丰富对于开源或者闭源模型的支持(目前暂时支持较弱)尤其是对于中文支持不错的国产模型比如ChatGLM2等,另外一种方案就是今天介绍的LangChain-Chatchat刚好可以与Quivr互补,其对于模型的支持很丰富,但对于业务端的属性支持较弱,只支持单个用户单个知识库,不能建立多个知识库通过权限来隔离。
当然不排除还有其它更合适的解决方案,至少开源的产品或多或少很难直接拿来作为生产级别去应用,还得需要进行二开去完善,大部分做的相对成熟的开源产品基本上都是走商业化路线,或者开源通过服务收费,比如模型微调训练,构建特定行业应用的大模型和对外提供模型API能力。
Quivr基于GPT和开源LLMs构建本地知识库(更新篇)
Danswer快速指南:不到15分钟打造您的企业级开源知识问答系统
GenossGPT简介:使用Genoss模型网关实现多个LLM模型的快速切换与集成
Cohere正式发布企业知识库助手Coral
基于ChatGLM-6B构建本地私有化离线知识库
Flowise|无代码ChatBot构建平台|LangChain
Quivr基于Supabase构建本地知识库
Quivr基于Supabase构建本地知识库
PrivateGPT:免费构建本地私有化知识库[部署教程]
在构建企业级知识库方面,有许多解决方案和产品可供选择,包括开源和闭源。这些解决方案的核心技术基于LangChain,如Quivr结合Supabase、PrivateGPT和ChatGLM6B等。同时,也有无代码平台Flowise,基于提供丰富的内置组件,帮助用户快速构建聊天机器人、智能客户和知识问答等应用。
为了解决模型扩展和维护的问题,StanGirard开发了Genoss,通过创建简单的API使得模型扩展能力完全解耦。此外,Danswer是一个开源项目,具有Connectors连接器优势,可以方便地将文档资料添加到向量数据库中进行索引。
在选择本地私有化模型时,清华大学开源的ChatGPT-6B模型对中文支持友好,并可在消费级显卡上运行。大语言模型的发展为智能客服、文档检索和代码搜索等场景提供了便利,提高了生产力。Coral这款AI知识库助手致力于解决企业痛点,重新定义生产力。
总之,在构建企业级知识库时,有多种解决方案可供选择。根据实际需求和场景来选择合适的方案,运用大语言模型的技术优势,提高企业生产力和效率。
二、介绍2.1、ChatGLM2-6BChatGLM2-6B是开源中英双语对话模型ChatGLM-6B的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B引入了如下新特性:
更强大的性能:基于ChatGLM初代模型的开发经验,我们全面升级了ChatGLM2-6B的基座模型。ChatGLM2-6B使用了GLM的混合目标函数,经过了1.4T中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B在MMLU(+23%)、CEval(+33%)、GSM8K(+571%)、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于FlashAttention技术,我们将基座模型的上下文长度(ContextLength)由ChatGLM-6B的2K扩展到了32K,并在对话阶段使用8K的上下文长度训练。对于更长的上下文,我们发布了ChatGLM2-6B-32K模型。LongBench的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K有着较为明显的竞争优势。
更高效的推理:基于Multi-QueryAttention技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了42%,INT4量化下,6G显存支持的对话长度由1K提升到了8K。
更开放的协议:ChatGLM2-6B权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
2.2、LangChain-Chatchat介绍LangChain-Chatchat(原Langchain-ChatGLM):基于Langchain与ChatGLM等大语言模型的本地知识库问答应用实现。一种利用LangChain思想实现的基于本地知识库的问答应用,其目标是期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
它的核心思路是通过使用FastChat接入Vicuna,Alpaca,LLaMA,Koala,RWKV等模型,然后依托于LangChain框架支持通过基于FastAPI提供的API调用服务,或使用基于Streamlit的WebUI进行操作。
依托于本项目支持的开源LLM与Embedding模型,全部可使用开源模型离线私有部署实现。与此同时,本项目也支持OpenAIGPTAPI的调用,并将在后续持续扩充对各类模型及模型API的接入。
本项目实现原理如下图所示,过程包括加载文件-读取文本-文本分割-文本向量化-问句向量化-在文本向量中匹配出与问句向量最相似的topk个-匹配出的文本作为上下文和问题一起添加到prompt中-提交给LLM生成回答。
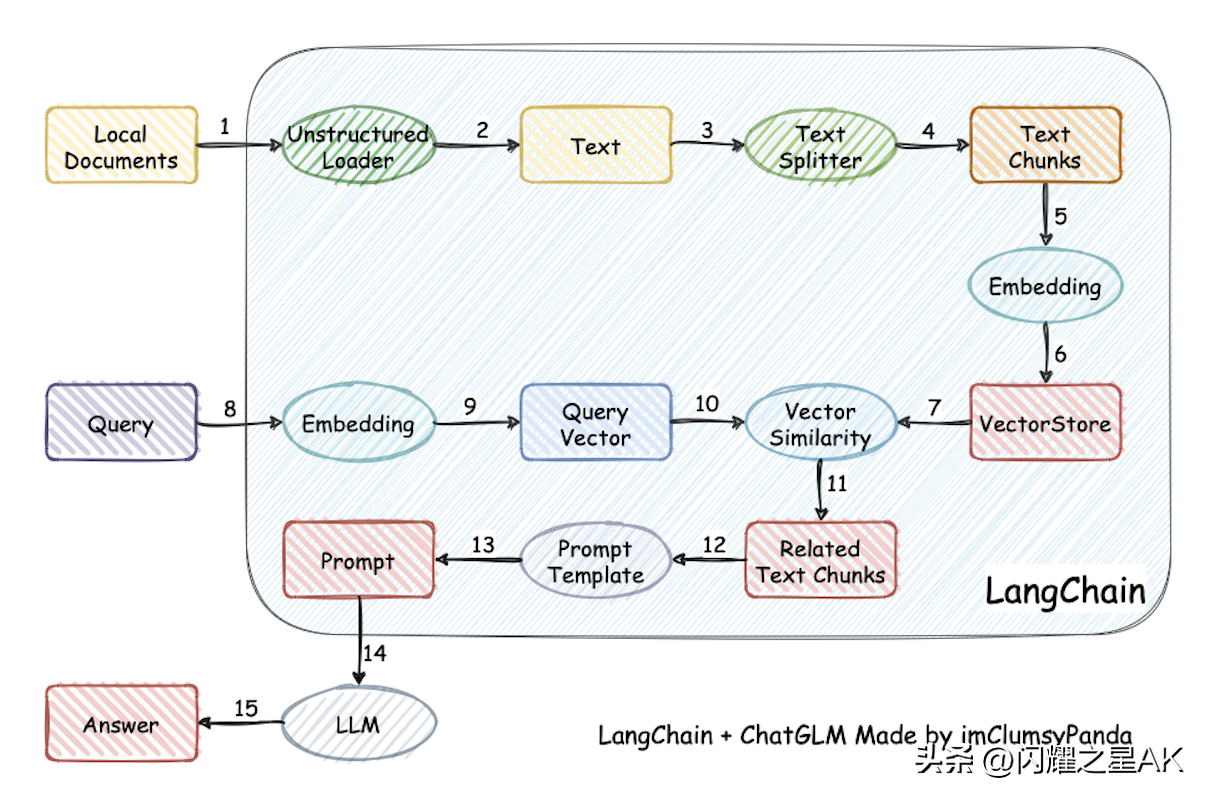
LangChain-Chatchat默认使用的LLM模型为THUDM/chatglm2-6b,默认使用的Embedding模型为moka-ai/m3e-base为例。
3.1、LLM模型支持目前最新的版本中基于FastChat进行本地LLM模型接入,目前已经正式接入支持的模型达30+,具体清单如下:
meta-llama/Llama-2-7b-chat-hf
Vicuna,Alpaca,LLaMA,Koala
BlinkDL/RWKV-4-Raven
camel-ai/CAMEL-13B-Combined-Data
databricks/dolly-v2-12b
FreedomIntelligence/phoenix-inst-chat-7b
h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
lcw99/
lmsys/
mosaicml/mpt-7b-chat
Neutralzz/BiLLa-7B-SFT
nomic-ai/gpt4all-13b-snoozy
NousResearch/Nous-Hermes-13b
openaccess-ai-collective/manticore-13b-chat-pyg
OpenAssistant/
project-baize/baize-v2-7b
Salesforce/codet5p-6b
StabilityAI/stablelm-tuned-alpha-7b
THUDM/chatglm-6b
THUDM/chatglm2-6b
tiiuae/falcon-40b
timdettmers/guanaco-33b-merged
togethercomputer/RedPajama-INCITE-7B-Chat
WizardLM/
WizardLM/
baichuan-inc/baichuan-7B
internlm/internlm-chat-7b
Qwen/Qwen-7B-Chat
HuggingFaceH4/starchat-beta
任何EleutherAI的pythia模型,如
在以上模型基础上训练的任何Peft适配器。为了激活,模型路径中必须有peft。注意:如果加载多个peft模型,你可以通过在任何模型工作器中设置环境变量PEFT_SHARE_BASE_WEIGHTS=true来使它们共享基础模型的权重。
以上模型支持列表可能随FastChat更新而持续更新,可参考FastChat已支持模型列表。
除本地模型外,本项目也支持直接接入OpenAIAPI,具体设置可参考configs/model_中的llm_model_dict的配置信息。
3.2、Embedding模型支持对于构建文本向量的模型,目前支持调用HuggingFace中的Embedding模型,目前已支持的Embedding模型达15+,具体支持清单如下:
moka-ai/m3e-small
moka-ai/m3e-base
moka-ai/m3e-large
BAAI/bge-small-zh
BAAI/bge-base-zh
BAAI/bge-large-zh
BAAI/bge-large-zh-noinstruct
text2vec-base-chinese-sentence
text2vec-base-chinese-paraphrase
text2vec-base-multilingual
shibing624/text2vec-base-chinese
GanymedeNil/text2vec-large-chinese
nghuyong/
nghuyong/
OpenAI/text-embedding-ada-002
四、项目部署4.1、环境说明这里就用阿里云的海外GPU服务器来演示如何部署基于ChatGLM2-6B本地知识库,服务器基本配置信息如下:
CPU:8核(vCPU)
内存:30GiB
GPU:NVIDIAA10显存24GB

如果是全新的服务器,首次需要安装Conda,在终端中,使用以下命令下载Miniconda安装脚本:
wget
使用以下命令运行安装脚本:
bashMiniconda3-latest-Linux-x86_64.sh
按照安装程序的提示进行安装。您可以选择安装位置和环境变量设置等选项。
安装完成后,关闭终端并重新打开一个新终端,在新终端中,使用以下命令激活conda环境:
source~/.bashrc
使用以下命令检查conda是否成功安装:
conda--version
如果conda成功安装,您将看到conda的版本号,我这里安装的是。
4.3、安装Python首先,确信你的机器安装了版本
如果没有安装或者低于这个版本,可使用conda安装环境
condacreate-p/opt/langchain-chatchat/pyenvpython=3.8
激活Python虚拟环境condaactivate/opt/langchain-chatchat/pyenv关闭环境condadeactivate/opt/langchain-chatchat/pyenvcondaactivate/opt/langchain-chatchat/pyenv(/opt/langchain-chatchat/pyenv)root@iZ6we:/opt/langchain-chatchat
更新py库
pip3install--upgradepip4.4、项目依赖
使用阿里源$$
安装依赖的时候可能会出现如下错误:
Couldnotfindaversionthatsatisfiestherequirementsetuptools_scm(fromversions:none)
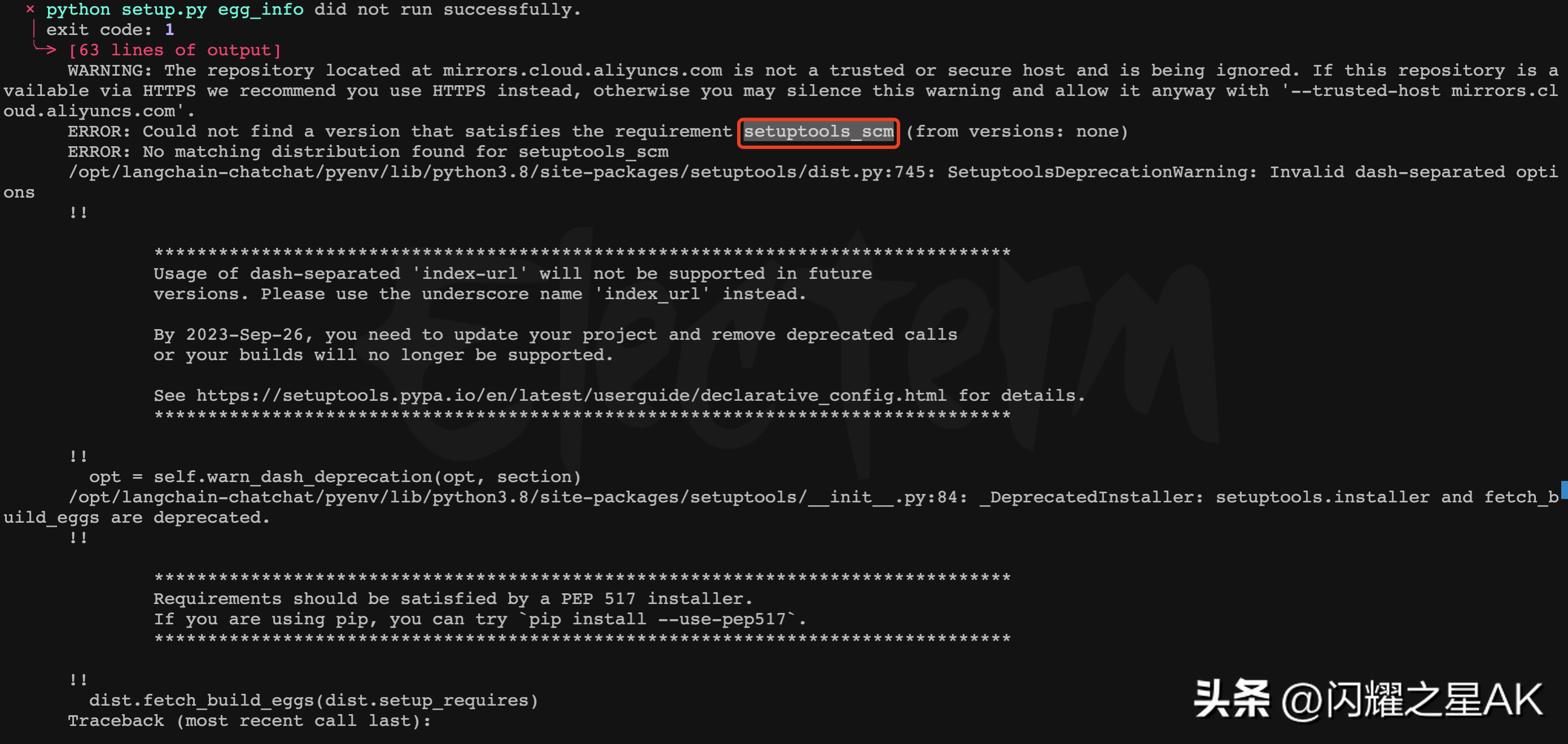
这个错误通常在安装或配置setuptools_scm包时遇到问题时出现。只需要重新安装setuptools_scm。
pipinstall--index-url4.5、下载模型
因为模型文件一般比较大(ChatGLM2-6B的模型权重文件差不多12G),首先需要先安装GitLFS
安装GitLFS。运行以下命令来安装GitLFS:sudoapt-getinstallgit-lfs如果成功安装,您将看到GitLFS的版本信息。git-lfs/3.4.0(GitHub;linuxamd64;)
下载模型放入指定文件目录中
"name"修改为FastChat服务中的"api_base_url""api_key":"EMPTY"}}
请确认已下载至本地的Embedding模型本地存储路径写在embedding_model_dict对应模型位置,如:
embedding_model_dict={"m3e-base":"/opt/langchain-chatchat/models/m3e-base",}如果你选择使用OpenAI的Embedding模型,请将模型的key写入embedding_model_dict中。使用该模型,你需要鞥能够访问OpenAI官的API,或设置代理。
4.7、知识库初始化当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
如果您是从0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding模型与configs/model_中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可:
$pythoninit_
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启normalize_L2,需要以下命令初始化或重建知识库:
$pythoninit_4.8、启动LLM服务
如需使用开源模型进行本地部署,需首先启动LLM服务,如果启动在线的API服务(如OPENAI的API接口),则无需启动LLM服务。
这里选择基于多进程脚本llm_启动LLM服务的方式,在项目根目录下,执行server/llm_脚本启动LLM模型服务:
$pythonserver/llm_
如果部署服务器具备单张或者多张GPU显卡,只需在llm_中修改create_model_worker_app函数中,修改如下三个参数:
gpus=None,num_gpus=1,max_gpu_memory="20GiB"
其中,gpus控制使用的显卡的ID,如果"0,1";num_gpus控制使用的卡数;max_gpu_memory控制每个卡使用的显存容量。
4.9、启动API服务在线调用API服务的情况下,直接执执行server/脚本启动API服务;
pythonserver/
启动API服务后,可访问localhost:7861或{API所在服务器IP}:7861FastAPI自动生成的docs进行接口查看与测试。
FastAPIdocs界面
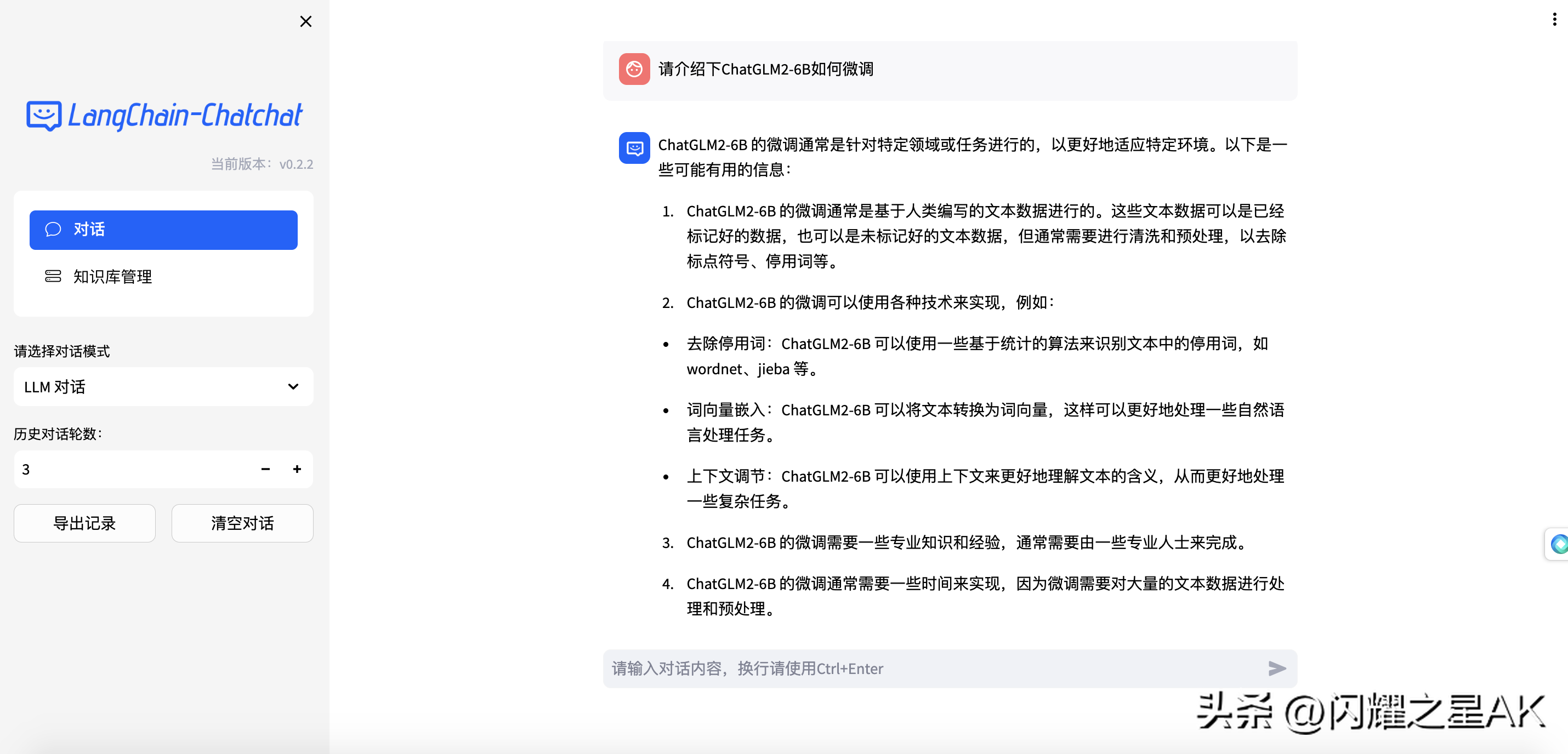
使用Langchain-Chatchat主题色启动WebUI服务(默认使用端口8501)
$"light"--"f5f5f5"--"#000000"
WebUI对话界面:
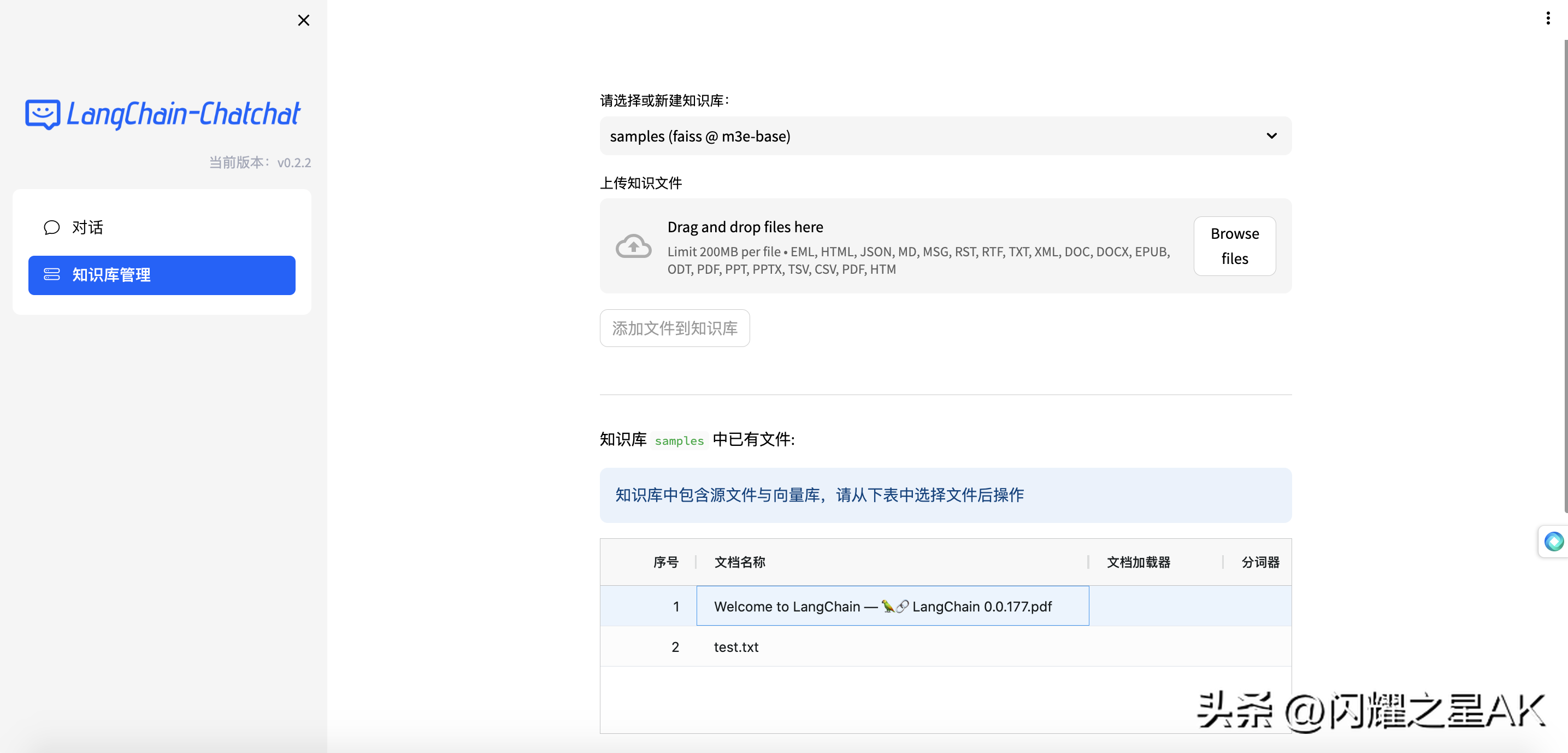
WebUI知识库管理页面:
说明:安装过程中如果遇到其它的问题,建议先去官方GitHub的FAQ中看看,大部分问题已经有解决方案了。五、Docker环境部署
如果想快速部署LangChain-Chatchat产品来体验,可以选择Docker一键部署的方式,比较简单,只需要先安装Docker容器,在Unbuntu环境中如何安装DockerDockerCompose,可以参考文章《Quivr基于GPT和开源LLMs构建本地知识库(更新篇)》中的3.2节。这里不过多赘述。Windows安装Docker更简单。
Docker镜像使用的版本一般会稍微滞后一些,如果想快速体验最新的版本按前面开发模式部署会更合适一点。
LangChain-Chatchat项目使用的Docker镜像地址是:
/chatchat/chatchat:0.2.0
dockerrun-d--gpusall-p80:8501/chatchat/chatchat:0.2.0
该版本镜像大小33.9GB,使用,以nvidia/cuda:12.1.1-为基础镜像
该版本内置一个embedding模型:m3e-large,内置chatglm2-6b-32k
该版本目标为方便一键部署使用,请确保您已经在Linux发行版上安装了NVIDIA驱动程序
请注意,您不需要在主机系统上安装CUDA工具包,但需要安装NVIDIADriver以及NVIDIAContainerToolkit,请参考安装指南
首次拉取和启动均需要一定时间,首次启动时请参照下图使用dockerlogs-fcontainerid查看日志
如遇到启动过程卡在Waiting..步骤,建议使用dockerexec-itcontaineridbash进入/logs/目录查看对应阶段日志
六、ReferencesChatGLM2-6B
LangChain-Chatchat
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。
本文链接:https://goko.jsntrg.cn/707784986058.html