微软的大模型太强了,数学推理超ChatGPT,论文、模型权重全公开


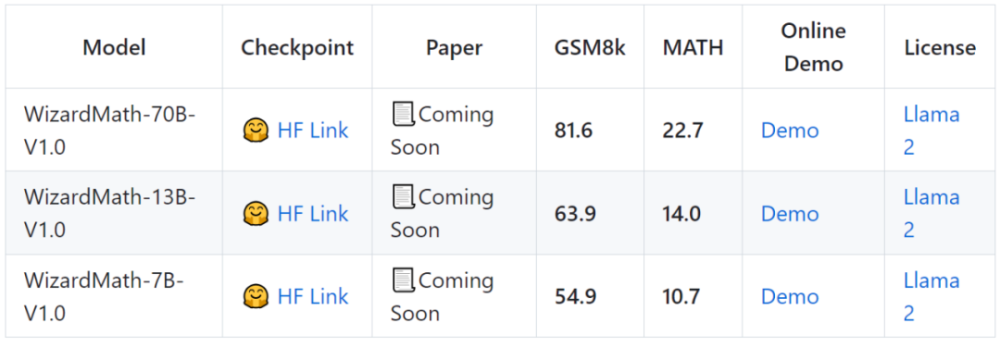
机器之心报道上周,微软与中国科学院联合发布的WizardMath大模型火了。该模型有70B、13B、7B三个参数规模,研究者在两个数学推理基准GSM8k和MATH上的测试表明,WizardMath优于......
机器之心报道
上周,微软与中国科学院联合发布的WizardMath大模型火了。
该模型有70B、13B、7B三个参数规模,研究者在两个数学推理基准GSM8k和MATH上的测试表明,WizardMath优于所有其他开源LLM,达到SOTA。
在GSM8K上,模型的性能略优于一些闭源LLM,包括、ClaudeInstant1和PaLM2540B。
模型在GSM8k基准测试中达到81.6pass@1,比SOTA开源LLM高出24.8分。
模型在MATH基准测试中达到22.7pass@1,比SOTA开源LLM高出9.2分。
其中,GSM8k数据集包含大约7500个训练数据和1319个测试数据,主要是小学水平的数学问题,每个数据集都包含基本算术运算(加、减、乘、除),一般需要2到8步来解决。MATH数据集来自AMC10、AMC12和AIME等著名数学竞赛当中的数学问题,包含7500个训练数据和5000个具有挑战性的测试数据:初等代数、代数、数论、几何、微积分等。
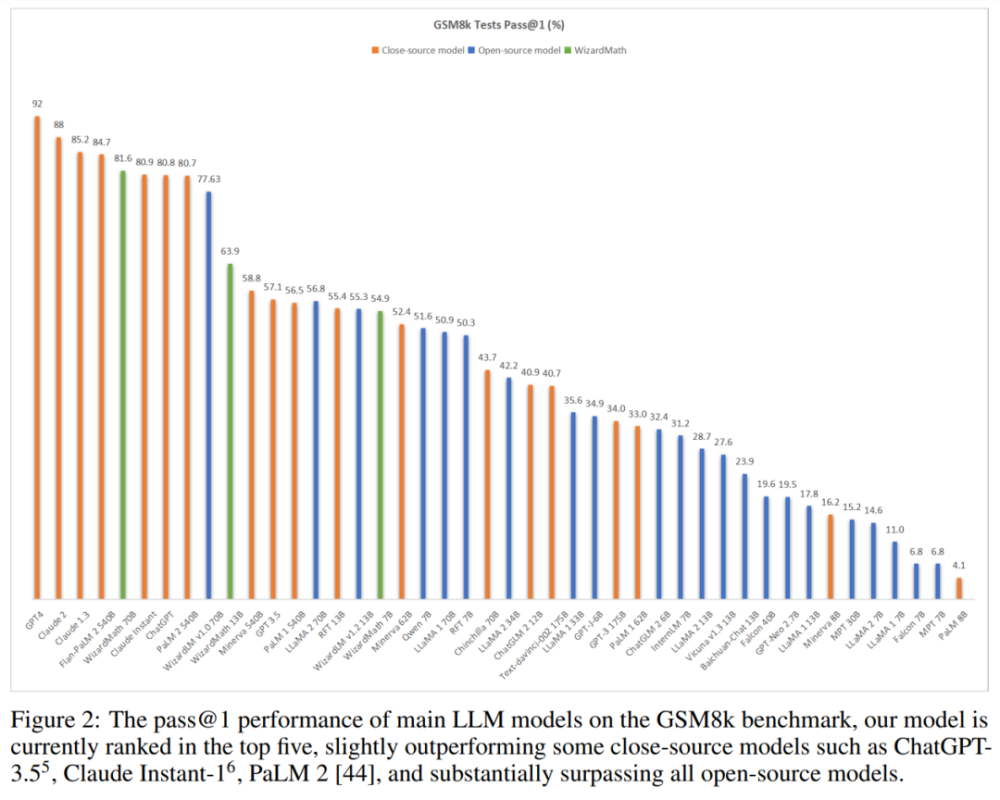
下图显示,WizardMath在GSM8k基准测试中获得第五名,超过了ClaudeInstant1(81.6)、ChatGPT(81.6)和PaLM2540B(81.6)。值得注意的是,与这些模型相比,WizardMath模型的尺寸要小得多。
HuggingFace已上线3个版本(分别为7B、13B和70B参数)。现在,相关论文已经公布了。

论文地址:
项目地址:
模型权重:
方法介绍
该研究提出了一种名为ReinforcedEvol-Instruct方法,如图1所示,其包含3个步骤:1、监督微调。2、训练指令奖励模型以及过程监督奖励模型。3、ActiveEvol-Instruct和PPO训练。
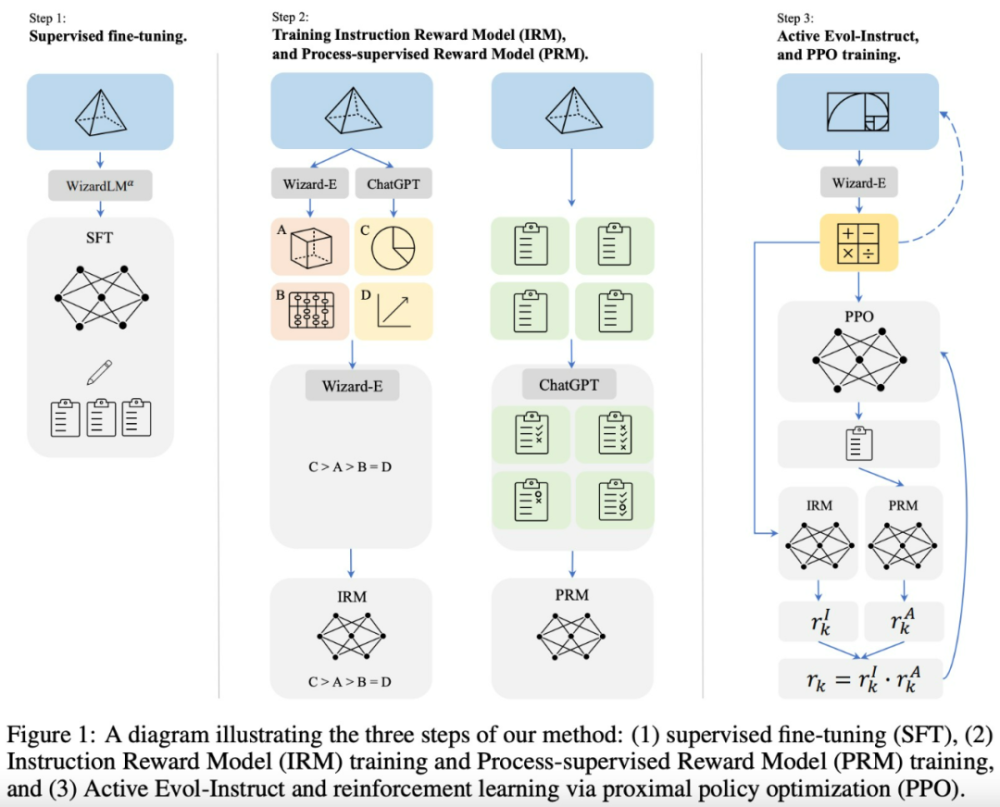
监督微调:继InstructGPT之后,该研究还使用了监督指令-响应对进行微调,其中包含:
为了使每个步骤的解析都更加容易,该研究使用Alpha版本的WizardLM70B(微调的LLaMA模型)模型对GSM8k和MATH重新生成了15k个答案,以step-by-step方式生成解决方案,然后找出正确答案,并使用这些数据对基础Llama模型进行微调。
该研究还从WizardLM的训练数据中采样了1.5k个开放域对话,然后将其与上述数学语料库合并作为最终的SFT(supervisedfine-tuning)训练数据。
Evol-Instruct原则:受WiazrdLM提出的Evol-Instruct方法及其在WizardCoder上有效应用的启发,该研究试图制作具有各种复杂性和多样性的数学指令,以增强预训练LLM。具体来说:
向下进化:首先是增强指令,通过使问题变得更加容易来实现。例如,i):将高难度问题转化为较低难度,或ii)用另一个不同主题制作一个新的更简单的问题。
向上进化:源自原始的Evol-Instruct方法,通过i)添加更多约束,ii)具体化,iii)增加推理来深化并产生新的更难的问题。
ReinforcedEvol-Instruct:受InstructGPT和PRMs的启发,该研究训练了两个奖励模型,分别用来预测指令的质量和答案中每一步的正确性。
实验及结果
该研究主要在GSM8k和MATH这两个常见的数学基准上测试了模型的性能,并使用大量基线模型,包括闭源模型:OpenAI的GPT-3、、ChatGPT、GPT-4,谷歌的PaLM2、PaLM、Minerva,Anthropic的ClaudeInstant、、Claude2,DeepMind的Chinchilla;开源模型:Llama1、Llama2、GAL、GPT-J、GPT-Neo、Vicuna、MPT、Falcon、Baichuan、ChatGLM、Qwen和RFT。
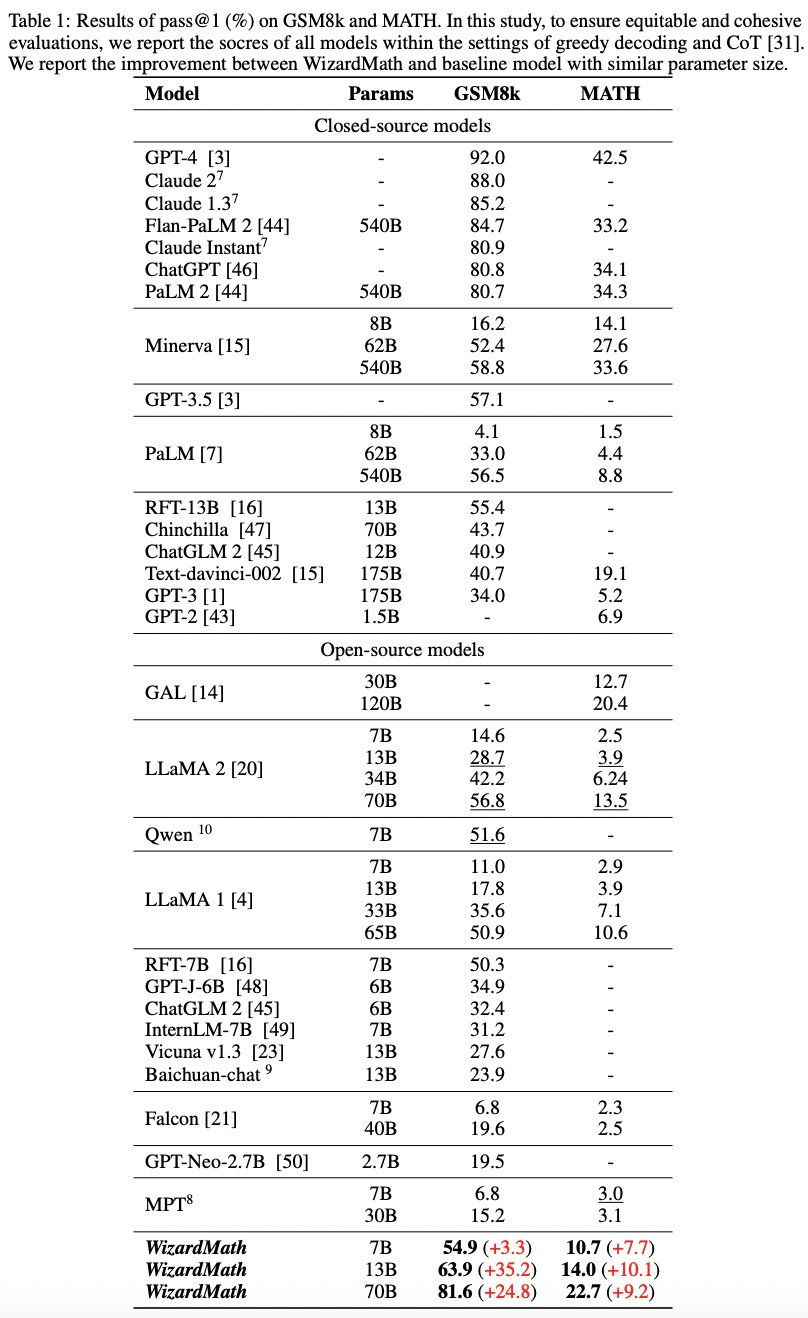
与闭源模型的比较。在表1中,WizardMath70B稍微优于GSM8k上的一些闭源LLM,包括ChatGPT、ClaudeInstant和PaLM2540B。
如图2所示(见上文),WizardMath目前在所有模型上排名前五。同时,WizardMath70B在MATH上也超越了Text-davinci-002。详细结果如下:
WizardMath13B在GSM8k上优于PaLM1540B(63.9)、Minerva540B(63.9)和(63.9)。同时,它在MATH上超越了PaLM1540B(14.0)、GPT-3175B(14.0)。
WizardMath70B在GSM8k上实现了与ClaudeInstant(81.6)、ChatGPT(81.6)和PaLM2(81.6)更好或相当的性能。同时,WizardMath70B在MATH基准测试中也超过了Text-davinci-002(22.7比19.1)。
与开源模型的比较。表1中所示的结果表明,WizardMath70B在GSM8k和MATH基准测试中明显优于所有开源模型。详细结果如下:
WizardMath7B超越了大多数开源模型,这些模型的参数数量约为7B到40B不等,包括MPT、Falcon、Baichuan-chat、、ChatGLM2、Qwen、Llama1和Llama2。尽管它的参数数量要少得多。
WizardMath13B在GSM8k上明显优于Llama165B(63.9)和Llama270B(63.9)。此外,它在MATH上的表现远远优于Llama165B(14.0)和Llama270B(14.0)。
WizardMath70B在GSM8k上超越了Llama270B(81.6比56.8),提升达到24.8%。同时,它在数学方面也比Llama270B(22.7比13.5)高出9.2%。
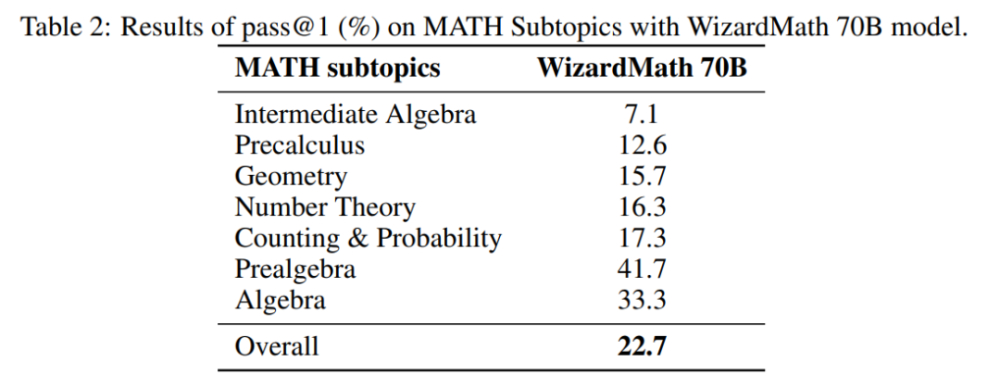
表2显示了WizardMath70B模型在MATHSubtopics上的结果。
本文链接:https://goko.jsntrg.cn/602793028323.html